Desbloqueando el Poder de tus Datos: Una Guía Práctica de Data Storytelling para Impulsar Decisiones de Negocio
¿Alguna vez te has sentido abrumado por una hoja de cálculo llena de números? ¿O quizás has preparado un informe con gráficos impecables, solo para darte cuenta de que tu audiencia no captó el mensaje clave? La verdad es que los datos por sí solos rara vez inspiran acción. Necesitan una voz, un propósito, una historia.
En el mundo actual, donde la información fluye a una velocidad vertiginosa, la capacidad de transformar datos brutos en narrativas convincentes no es solo una habilidad deseable, es una necesidad crítica para cualquier profesional que busque impactar en las decisiones de negocio. Aquí es donde entra el Data Storytelling.
El Data Storytelling es mucho más que crear visualizaciones bonitas. Es el arte de construir una narrativa en torno a tus datos para comunicar insights de manera clara, memorable y persuasiva. Es el puente entre el análisis frío y la comprensión humana, permitiendo que tus descubrimientos se traduzcan en estrategias accionables.
En este artículo, te guiaré a través de las mejores prácticas para desentrañar las historias ocultas en tus datos. Desde entender a tu audiencia hasta construir visualizaciones impactantes y tejer una narrativa coherente, descubrirás cómo el Data Storytelling puede transformar la forma en que presentas y utilizas la información para impulsar un cambio real.
Metodología: El Mapa para una Narrativa de Datos Exitosa
Contar historias con datos puede parecer intimidante al principio, pero siguiendo un proceso estructurado, te darás cuenta de que es una habilidad que se puede aprender y perfeccionar. Aquí te presento mi metodología, los pasos que yo mismo sigo para convertir datos en narrativas convincentes.
Paso 1: Conoce a tu Audiencia y Define tu Mensaje
Antes de siquiera tocar un dato, pregúntate: ¿Para quién es esta historia? ¿Qué necesitan saber? ¿Qué acción quiero que tomen? Un mensaje claro y conciso es la columna vertebral de tu narrativa. Define el “por qué” detrás de tus datos. ¿Es para informar, persuadir o inspirar? Conocer a tu audiencia te ayudará a elegir el tono, el nivel de detalle y las visualizaciones más apropiadas.
Paso 2: Explora, Limpia y Encuentra el “Oro” en tus Datos
Tus datos son la materia prima. Como un buen orfebre, yo realizo un Análisis Exploratorio de Datos (EDA) para identificar patrones, tendencias, anomalías y las relaciones que formarán la base de tu historia. Asegúrate de que tus datos sean limpios y confiables. Datos sucios o incompletos pueden arruinar la mejor de las narrativas. Busca los “insights” clave, esas pepitas de oro que son la base de tu historia.
Paso 3: Visualiza con Propósito: El Lienzo de tu Narrativa
Una visualización efectiva no es solo un gráfico, es una ventana a tus insights. Elige el tipo de gráfico adecuado para tu mensaje (líneas para tendencias, barras para comparaciones, dispersión para relaciones). Yo siempre me enfoco en la claridad, la simplicidad y en resaltar los puntos clave. Evito el “ruido” innecesario; cada elemento en mi gráfico debe servir a un propósito narrativo.
Paso 4: Teje la Narrativa: El Hilo Conductor
Aquí es donde el Data Storytelling cobra vida. Yo organizo mis visualizaciones de manera lógica, creando un flujo que guíe al lector desde la introducción del problema hasta la solución o la recomendación. Utilizo títulos impactantes, subtítulos descriptivos y anotaciones directas en mis gráficos para enfatizar los puntos importantes y conectar los datos con mi mensaje central. Pienso en mi historia con un comienzo, un nudo y un desenlace, como si fuera una novela.
Paso 5: Practica, Recibe Feedback y Perfecciona
Como cualquier habilidad, el Data Storytelling mejora con la práctica. Comparto mi historia con otros, solicito feedback sobre la claridad y el impacto, y no dudo en iterar. La perfección no es el objetivo, la comprensión y la acción sí lo son. Siempre hay espacio para mejorar y hacer que mi historia sea aún más resonante.
Códigos y Ejemplos Prácticos: De Datos Crudos a Narrativas Claras
Para ilustrar estos principios, vamos a sumergirnos en algunos ejemplos prácticos utilizando Python y sus poderosas librerías de visualización. He elegido datasets simples para que el foco permanezca en la narrativa y no en la complejidad de los datos, lo que te permitirá concentrarte en el “cómo” contar la historia.
Ejemplo 1: Descifrando las Especies de Flores Iris
Imagina que soy un botánico intentando entender las diferencias entre distintas especies de flores Iris. A simple vista, todas parecen similares, pero los datos pueden revelarme patrones distintivos. Usaré el famoso dataset Iris para explorar cómo las medidas de sus sépalos y pétalos me ayudan a diferenciarlas.
Primero, cargo el dataset y echo un vistazo rápido a sus datos. Esto me da una idea de qué información tengo.
import seaborn as sns
import matplotlib.pyplot as plt
# Cargar el dataset Iris
iris = sns.load_dataset('iris')
# Mostrar las primeras filas y estadísticas descriptivas
print("Primeras 5 filas del dataset Iris:")
print(iris.head())
print("\nEstadísticas descriptivas del dataset Iris:")
print(iris.describe())
print("\nConteo de especies:")
print(iris['species'].value_counts())
Primeras 5 filas del dataset Iris:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
Estadísticas descriptivas del dataset Iris:
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
Conteo de especies:
species
setosa 50
versicolor 50
virginica 50
Name: count, dtype: int64Ahora, la magia comienza con la visualización. Un gráfico de dispersión de la longitud del sépalo vs. la longitud del pétalo, coloreado por especie, me revela inmediatamente algo fascinante:
plt.figure(figsize=(10, 6))
sns.scatterplot(x='sepal_length', y='petal_length', hue='species', data=iris, s=100, alpha=0.8)
plt.title('Relación entre Longitud del Sépalo y Pétalo por Especie de Iris')
plt.xlabel('Longitud del Sépalo (cm)')
plt.ylabel('Longitud del Pétalo (cm)')
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(title='Especie')
plt.show()
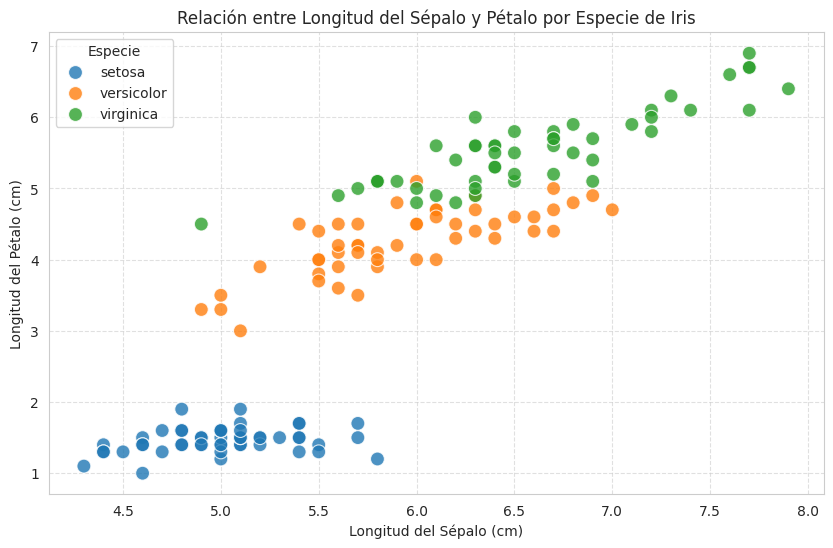
Insight Clave: Puedo observar claramente que la especie ‘setosa’ se agrupa en una región muy distinta, con pétalos mucho más cortos. ‘Versicolor’ y ‘virginica’ tienen cierta superposición, pero ‘virginica’ tiende a tener pétalos y sépalos más largos. Este simple gráfico ya me cuenta una historia de diferenciación que puedo usar para clasificar nuevas flores.
Para una visión más holística, un ‘pairplot’ me muestra las relaciones entre todas las combinaciones de características, lo que es invaluable en el EDA.
sns.pairplot(iris, hue='species', diag_kind='kde')
plt.suptitle('Pairplot del Dataset Iris por Especie', y=1.02) # Ajustar el título para que no se superponga
plt.show()
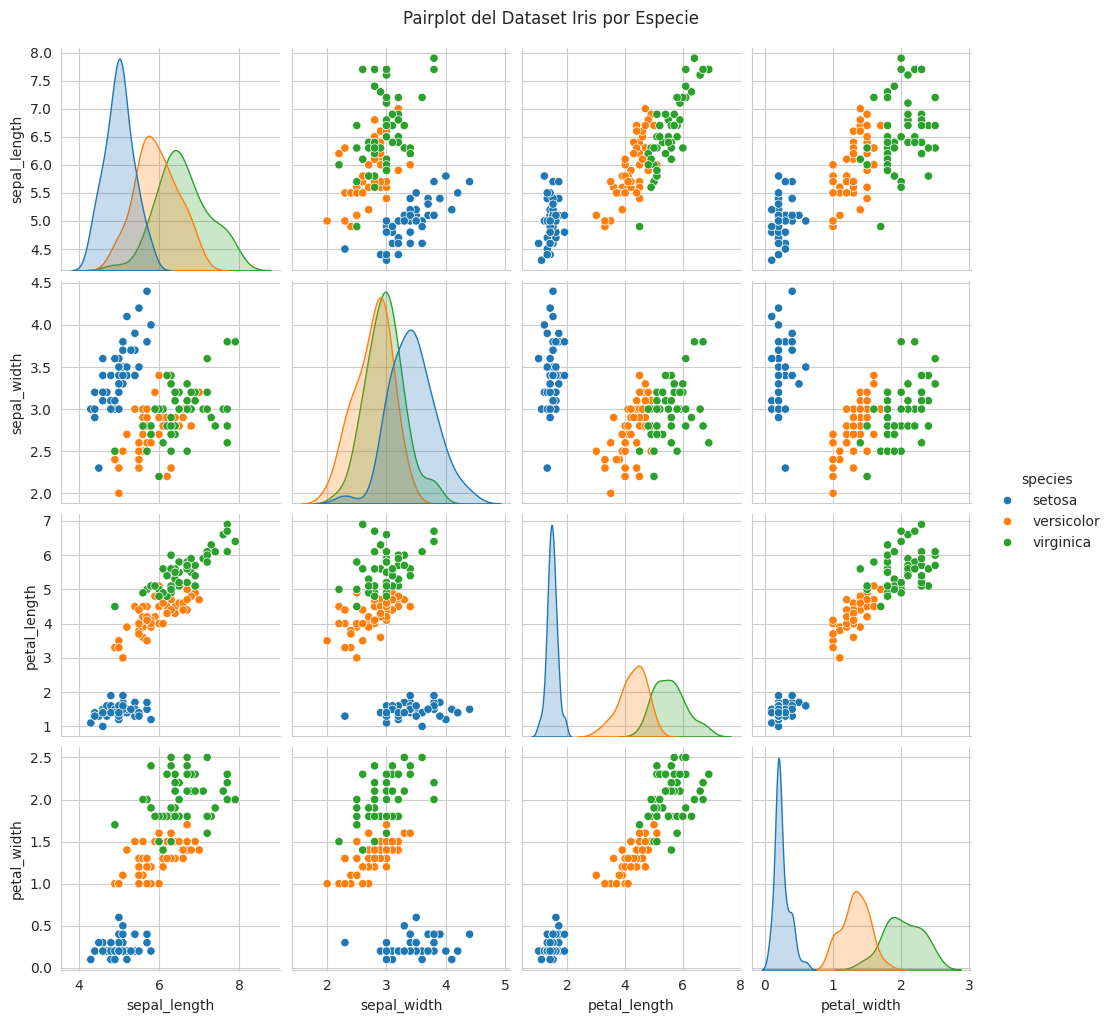
Insight Clave: El pairplot confirma y expande mi entendimiento. Veo que las características del pétalo (ancho y largo) son los discriminadores más fuertes entre las especies. La distribución de cada característica también es reveladora. Esta exploración visual me permite identificar rápidamente qué características son más informativas para mi “historia” de clasificación.
Ejemplo 2: Entendiendo el Comportamiento de las Propinas en un Restaurante
Ahora, cambiemos de escenario y entremos a un restaurante. Como dueño o gerente, quiero entender mejor el comportamiento de las propinas: ¿Hay días específicos donde se propina más? ¿Afecta el hecho de que alguien fume? ¿O la hora del día? Los datos del dataset ‘tips’ me ayudarán a responder estas preguntas.
Cargo el dataset ‘tips’, que contiene información sobre las propinas dadas en un restaurante.
import seaborn as sns
import matplotlib.pyplot as plt
# Cargar el dataset Tips
tips = sns.load_dataset('tips')
# Mostrar las primeras filas y estadísticas descriptivas
print("Primeras 5 filas del dataset Tips:")
print(tips.head())
print("\nEstadísticas descriptivas del dataset Tips:")
print(tips.describe())
print("\nConteo de 'day':")
print(tips['day'].value_counts())
Primeras 5 filas del dataset Tips:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Estadísticas descriptivas del dataset Tips:
total_bill tip size
count 244.000000 244.000000 244.000000
mean 19.785943 2.998279 2.569672
std 8.902412 1.383638 0.951100
min 3.070000 1.000000 1.000000
25% 13.347500 2.000000 2.000000
50% 17.795000 2.900000 2.000000
75% 24.127500 3.562500 3.000000
max 50.810000 10.000000 6.000000
Conteo de 'day':
day
Sat 87
Sun 76
Thur 62
Fri 19
Name: count, dtype: int64Comencemos observando la distribución de propinas a lo largo de la semana.
plt.figure(figsize=(10, 6))
sns.boxplot(x='day', y='tip', data=tips, palette='viridis')
plt.title('Distribución de Propinas por Día de la Semana')
plt.xlabel('Día de la Semana')
plt.ylabel('Propina ($)')
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.show()
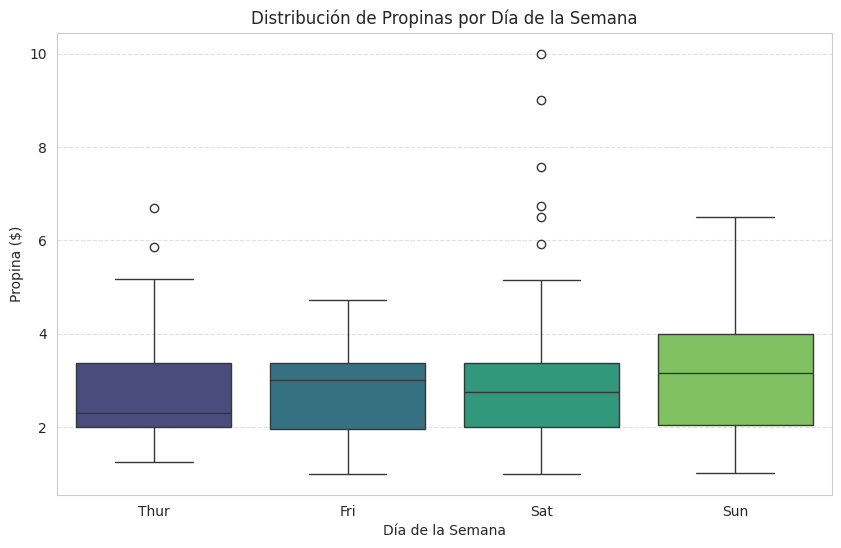
Insight Clave: Los fines de semana (viernes, sábado, domingo) muestran una dispersión más amplia y medianas de propina ligeramente más altas en comparación con el jueves. Esto me sugiere que los clientes son más generosos, o que las cuentas son más altas, los fines de semana. ¡Una oportunidad para concentrar personal o promociones!
¿Qué hay de la relación entre la cuenta total y la propina? Y, ¿influye si el cliente es fumador o no?
plt.figure(figsize=(10, 6))
sns.scatterplot(x='total_bill', y='tip', hue='smoker', data=tips, s=100, alpha=0.7)
plt.title('Relación entre Cuenta Total y Propina (Fumadores vs. No Fumadores)')
plt.xlabel('Cuenta Total ($)')
plt.ylabel('Propina ($)')
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend(title='Fumador')
plt.show()
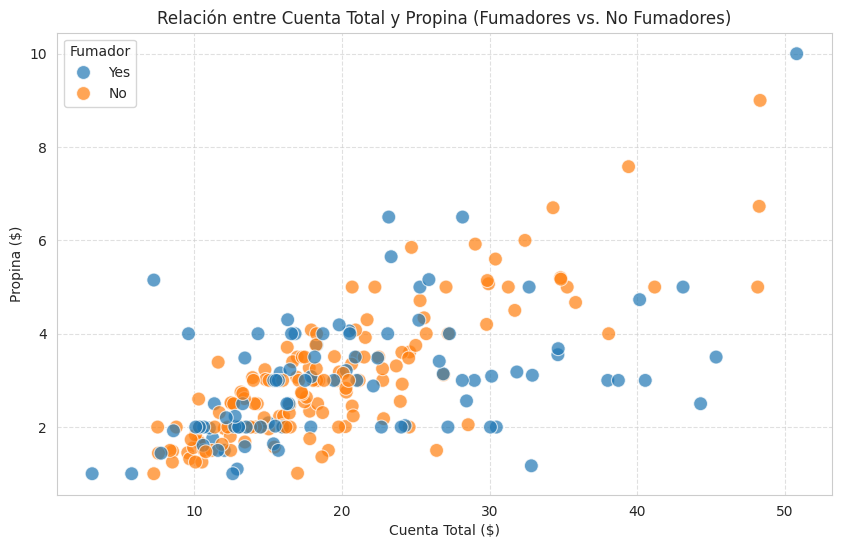
Insight Clave: Existe una clara correlación positiva: a mayor cuenta total, mayor es la propina. Interesantemente, no parece haber una diferencia significativa en el patrón de propinas entre fumadores y no fumadores en relación con la cuenta total; ambos grupos siguen la misma tendencia. Esto me dice que puedo enfocarme en aumentar el valor de la cuenta, independientemente del hábito de fumar.
Finalmente, veamos si la hora del día influye en la propina promedio.
plt.figure(figsize=(8, 5))
sns.barplot(x='time', y='tip', data=tips, estimator=lambda x: sum(x)/len(x), palette='cividis') # Usar lambda para promedio
plt.title('Propina Promedio por Franja Horaria')
plt.xlabel('Franja Horaria')
plt.ylabel('Propina Promedio ($)')
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.show()
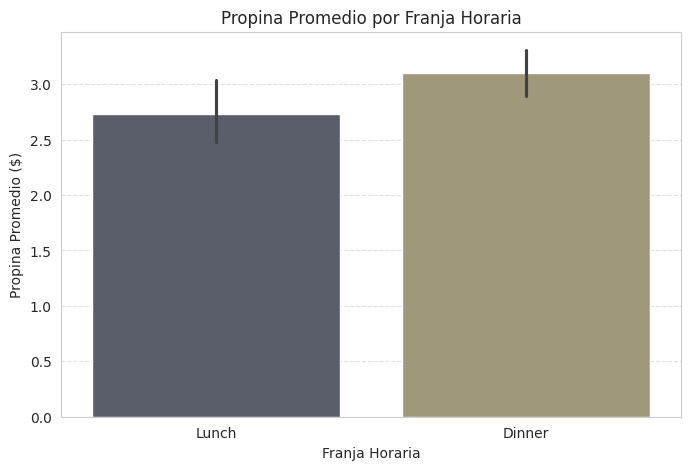
Insight Clave: Las propinas promedio son notablemente más altas durante la cena (‘Dinner’) en comparación con el almuerzo (‘Lunch’). Esto podría deberse a que las cuentas en la cena son generalmente más grandes, lo que lleva a propinas más grandes, o a una percepción de servicio diferente. Esta información es valiosa para la asignación de personal o para diseñar promociones específicas por franja horaria.
Conclusiones: Tu Voz, el Impacto de tus Datos
Como has visto a través de estos ejemplos, el Data Storytelling no es una moda pasajera; es una habilidad fundamental que te permitirá ir más allá del análisis técnico para convertirte en un comunicador persuasivo. Tus datos tienen historias que contar, y tú eres el narrador. Al dominar el arte de la narrativa de datos, no solo iluminarás insights, sino que también inspirarás acciones y generarás un impacto real en tu organización o en cualquier proyecto que emprendas.
Recuerda que la verdadera potencia de los datos no reside en su volumen o complejidad, sino en la capacidad de transformar esa información en conocimiento accionable, presentado de una manera que resuene con tu audiencia. ¡Empieza hoy mismo a practicar y verás cómo tus datos cobran vida!
recuerda que siempre siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.