¡Hola a todos y bienvenidos a un nuevo artículo en Sunday the Quant! Hoy vamos a sumergirnos en uno de esos temas que, aunque fundamentales, a veces pasamos por alto en nuestro camino hacia modelos de Machine Learning robustos y precisos: la gestión avanzada de datos faltantes. Como siempre digo, los datos son el alma de cualquier proyecto de ciencia de datos, y si esa alma está incompleta, nuestros modelos sufrirán las consecuencias. Acompáñenme mientras exploramos cómo transformar datos “rotos” en activos valiosos.
Introducción: El Silencio en los Datos y Por Qué Nos Importa
En el fascinante mundo del Machine Learning, los datos son nuestra materia prima. Recopilamos, limpiamos, transformamos y modelamos. Sin embargo, no todo es siempre perfecto. Es común que nuestros datasets presenten “agujeros”, es decir, valores faltantes. Estos no son solo una molestia; pueden ser un verdadero dolor de cabeza que sesga nuestros análisis, reduce la potencia estadística de nuestros modelos y, en el peor de los casos, lleva a conclusiones erróneas. Imaginen construir un modelo predictivo sobre datos donde la mitad de la información clave simplemente no existe. El resultado sería, en el mejor de los casos, inútil.
La presencia de valores faltantes puede deberse a diversas razones: errores en la entrada de datos, fallos en los sensores, falta de respuesta en encuestas, o simplemente información no aplicable a ciertas observaciones. Comprender el mecanismo detrás de estos valores faltantes es crucial, ya que impacta directamente en cómo debemos abordarlos:
- MCAR (Missing Completely at Random): La probabilidad de que un valor falte no depende de ninguna variable observable ni del valor de la variable faltante en sí. Es como si faltaran al azar, sin ningún patrón.
- MAR (Missing at Random): La probabilidad de que un valor falte depende de otras variables observadas en el dataset, pero no del valor de la variable faltante si esta hubiera sido observada. Por ejemplo, si los hombres son menos propensos a responder una pregunta sobre salarios, pero dentro de los hombres, la falta de respuesta no se relaciona con su salario real.
- MNAR (Missing Not at Random): La probabilidad de que un valor falte depende del valor de la variable faltante en sí, incluso después de controlar otras variables. Este es el caso más problemático, ya que el valor faltante en sí mismo contiene información. Por ejemplo, personas con salarios muy altos o muy bajos son menos propensas a revelar sus ingresos.
Tradicionalmente, hemos recurrido a métodos básicos para manejar estos vacíos: eliminar filas o columnas con datos faltantes (lo que puede llevar a una pérdida significativa de información o sesgo), o imputar con la media, mediana o moda. Si bien estos métodos son rápidos y sencillos, a menudo son demasiado simplistas y no capturan la complejidad subyacente de las relaciones en los datos. Es aquí donde entran en juego las técnicas avanzadas de imputación, permitiéndonos rellenar esos vacíos de una manera más inteligente y preservando la integridad de nuestros datos.
Metodología y Técnicas de Imputación Avanzada
Para ilustrar el poder de las técnicas avanzadas, he seleccionado dos datasets clásicos con datos faltantes significativos. Primero, el famoso dataset del Titanic, que nos ofrece un escenario real donde la información sobre la edad y la cabina de los pasajeros a menudo falta. Segundo, el dataset de Diabetes de los Indios Pima, un conjunto de datos médicos donde los valores cero en ciertas columnas (que lógicamente no deberían ser cero, como la presión arterial o la glucosa) en realidad representan datos faltantes. Después de explorar estos datasets, profundizaremos en la teoría y la implementación práctica de MICE, KNN Imputer, Iterative Imputer y MissForest.
Datasets Seleccionados
A continuación, les muestro cómo cargar y una breve exploración inicial de los datasets que usaremos. Es importante destacar que para el dataset Pima, interpretaremos los valores ‘0’ en columnas específicas como datos faltantes.
Dataset 1: Titanic
Este dataset es un clásico para problemas de clasificación y, por supuesto, para el manejo de datos faltantes. Las columnas ‘Age’, ‘Cabin’ y ‘Embarked’ suelen tener valores ausentes.
Carga y Exploración:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Cargar el dataset de Titanic
df_titanic = sns.load_dataset('titanic')
print("Forma original del dataset Titanic:", df_titanic.shape)
print("\nValores faltantes iniciales en Titanic:")
print(df_titanic.isnull().sum()[df_titanic.isnull().sum() > 0])
# Visualización de datos faltantes (matriz)
plt.figure(figsize=(10, 6))
sns.heatmap(df_titanic.isnull(), cbar=False, cmap='viridis')
plt.title('Valores Faltantes en el Dataset Titanic (Antes de Imputación)')
plt.show()Forma original del dataset Titanic: (891, 15)
Valores faltantes iniciales en Titanic:
age 177
embarked 2
deck 688
embark_town 2
dtype: int64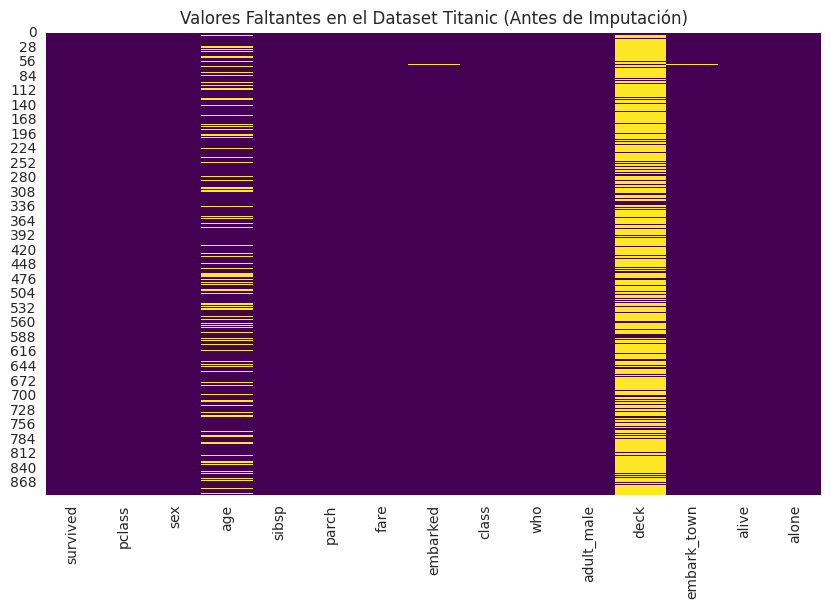
Dataset 2: Pima Indians Diabetes
Este dataset contiene información de pacientes y un indicador de si desarrollaron diabetes. Varias columnas numéricas tienen ‘0’ como valor, lo cual es lógicamente incorrecto y representa un valor faltante. Identificaremos y trataremos ‘0’ en ‘Glucose’, ‘BloodPressure’, ‘SkinThickness’, ‘Insulin’, y ‘BMI’ como NaN.
Carga y Exploración:
# Cargar el dataset Pima Indians Diabetes
# Columnas: embarazos, glucosa, presión arterial, grosor de la piel, insulina, BMI, función del pedigrí de diabetes, edad, resultado
column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
df_pima = pd.read_csv('https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv', names=column_names)
print("\nForma original del dataset Pima:", df_pima.shape)
print("\nValores '0' en columnas clave (inicialmente):")
for col in ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']:
print(f"- {col}: {(df_pima[col] == 0).sum()} ceros")
# Reemplazar '0' por NaN en columnas específicas
for col in ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']:
df_pima[col] = df_pima[col].replace(0, np.nan)
print("\nValores faltantes en Pima (después de reemplazar '0' por NaN):")
print(df_pima.isnull().sum()[df_pima.isnull().sum() > 0])
# Visualización de datos faltantes (matriz)
plt.figure(figsize=(10, 6))
sns.heatmap(df_pima.isnull(), cbar=False, cmap='viridis')
plt.title('Valores Faltantes en el Dataset Pima (Después de reemplazar 0 por NaN)')
plt.show()Forma original del dataset Pima: (768, 9)
Valores '0' en columnas clave (inicialmente):
- Glucose: 5 ceros
- BloodPressure: 35 ceros
- SkinThickness: 227 ceros
- Insulin: 374 ceros
- BMI: 11 ceros
Valores faltantes en Pima (después de reemplazar '0' por NaN):
Glucose 5
BloodPressure 35
SkinThickness 227
Insulin 374
BMI 11
dtype: int64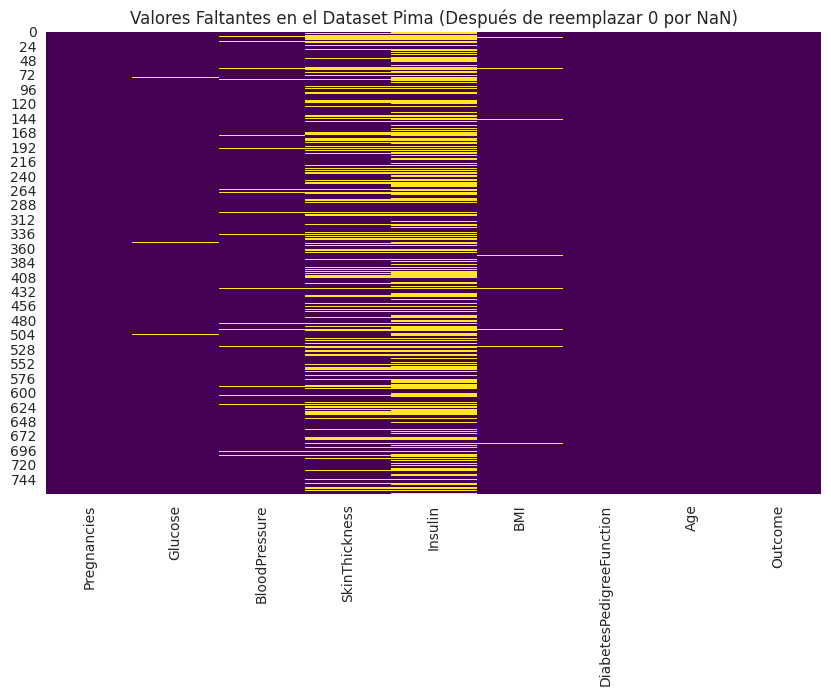
Técnicas Avanzadas de Imputación
1. KNN Imputer
Funcionamiento: El KNN Imputer (K-Nearest Neighbors Imputer) es un método de imputación basado en la proximidad. Para imputar un valor faltante en una característica de una observación, busca los ‘k’ vecinos más cercanos a esa observación en el espacio de características (utilizando las características que no faltan) y luego imputa el valor faltante con el promedio (para variables numéricas) o la moda (para categóricas) de los valores de esa característica entre esos ‘k’ vecinos. Es intuitivo y efectivo para capturar la estructura local de los datos.
Ventajas:
- Captura relaciones complejas en los datos, ya que utiliza la similitud entre observaciones.
- No requiere la construcción de un modelo predictivo explícito para cada característica.
Desventajas:
- Puede ser computacionalmente costoso en datasets grandes o con muchas características, ya que implica calcular distancias entre observaciones.
- Sensible a la escala de las características; es recomendable escalar los datos antes de aplicar KNN Imputer.
- La elección de ‘k’ (número de vecinos) puede influir significativamente en el resultado.
Casos de Uso: Ideal cuando se espera que los valores faltantes estén correlacionados con la estructura local de los datos y cuando se tienen suficientes datos para encontrar vecinos significativos.
Ejemplo de Código (Titanic – columna ‘Age’):
from sklearn.impute import KNNImputer
# Seleccionar columnas numéricas para imputación en Titanic
df_titanic_num = df_titanic[['Age', 'Fare', 'SibSp', 'Parch']].copy()
# Crear una copia para la imputación KNN
df_titanic_knn = df_titanic_num.copy()
# Inicializar KNNImputer
# n_neighbors: número de vecinos a usar
# weights: 'uniform' o 'distance'
knn_imputer = KNNImputer(n_neighbors=5)
# Imputar los valores faltantes
df_titanic_knn_imputed = pd.DataFrame(knn_imputer.fit_transform(df_titanic_knn), columns=df_titanic_knn.columns)
print("\nValores faltantes en Titanic (Age) después de KNN Imputer:")
print(df_titanic_knn_imputed.isnull().sum())
# Visualización antes y después (Histograma para 'Age')
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(df_titanic_num['Age'].dropna(), kde=True)
plt.title('Distribución de Edad (Antes de KNN Imputer)')
plt.subplot(1, 2, 2)
sns.histplot(df_titanic_knn_imputed['Age'], kde=True, color='orange')
plt.title('Distribución de Edad (Después de KNN Imputer)')
plt.tight_layout()
plt.show()2. Iterative Imputer (MICE)
Funcionamiento: El Iterative Imputer de scikit-learn es una implementación del enfoque de Ecuaciones Encadenadas Múltiples (MICE – Multiple Imputation by Chained Equations). Funciona iterativamente: para cada característica que tiene valores faltantes, se entrena un regresor (o clasificador) utilizando las otras características completas como predictores para estimar los valores faltantes de esa característica. Este proceso se repite para todas las características con valores faltantes en varias rondas, refinando las imputaciones en cada iteración hasta que las imputaciones convergen o se alcanza un número máximo de iteraciones. Permite especificar el estimador que se utilizará para las predicciones (por defecto, BayesianRidge, pero se pueden usar otros como RandomForestRegressor).
Ventajas:
- Considera las relaciones multivariadas entre todas las características, produciendo imputaciones más consistentes y precisas.
- Es muy flexible, ya que permite elegir el modelo predictivo subyacente para la imputación.
- Puede manejar diferentes tipos de datos (numéricos y categóricos, con el estimador adecuado).
Desventajas:
- Puede ser computacionalmente intensivo y lento, especialmente con datasets grandes y un alto número de iteraciones.
- El rendimiento depende en gran medida del estimador seleccionado.
Casos de Uso: Excelente para datasets donde las relaciones entre variables son complejas y se busca una imputación de alta calidad que conserve la estructura de los datos.
Ejemplo de Código (Pima – múltiples columnas):
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.linear_model import BayesianRidge
# Seleccionar columnas numéricas con NaN para imputación en Pima
columns_to_impute_pima = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
df_pima_impute = df_pima[columns_to_impute_pima].copy()
# Inicializar IterativeImputer con un estimador (BayesianRidge es el predeterminado)
iterative_imputer = IterativeImputer(BayesianRidge(), max_iter=10, random_state=0)
# Imputar los valores faltantes
df_pima_iterative_imputed = pd.DataFrame(iterative_imputer.fit_transform(df_pima_impute), columns=columns_to_impute_pima)
print("\nValores faltantes en Pima después de Iterative Imputer (MICE):")
print(df_pima_iterative_imputed.isnull().sum())
# Visualización de la distribución de 'Glucose' antes y después
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(df_pima_impute['Glucose'].dropna(), kde=True)
plt.title('Distribución de Glucosa (Antes de MICE)')
plt.subplot(1, 2, 2)
sns.histplot(df_pima_iterative_imputed['Glucose'], kde=True, color='green')
plt.title('Distribución de Glucosa (Después de MICE)')
plt.tight_layout()
plt.show()Valores faltantes en Pima después de Iterative Imputer (MICE):
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
dtype: int64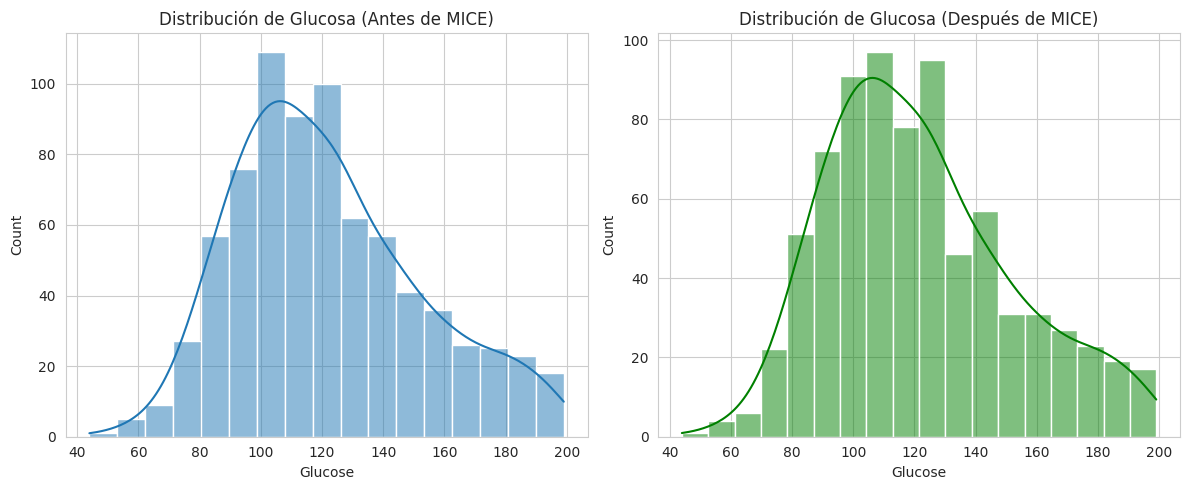
3. MissForest (Técnica Basada en Machine Learning)
Funcionamiento: MissForest es una técnica de imputación no paramétrica que utiliza el algoritmo Random Forest para imputar los valores faltantes. Para cada característica con valores faltantes, entrena un modelo Random Forest utilizando las características observadas del dataset como predictores y la característica con faltantes como variable objetivo. Las predicciones del Random Forest se utilizan para imputar los valores faltantes. Este proceso se repite iterativamente: en cada iteración, los valores imputados de la ronda anterior se utilizan para entrenar los modelos Random Forest de la ronda actual, hasta que la imputación converge o se alcanza un máximo de iteraciones. Es robusto y puede manejar tanto variables numéricas como categóricas.
Ventajas:
- No hace suposiciones paramétricas sobre la distribución de los datos, lo que lo hace muy flexible.
- Puede manejar de forma nativa tanto variables numéricas como categóricas.
- Es robusto a la presencia de valores atípicos y a relaciones no lineales entre las características.
- Generalmente produce imputaciones de muy alta calidad.
Desventajas:
- Puede ser computacionalmente costoso y lento, especialmente en datasets grandes o con un gran número de valores faltantes, debido a la naturaleza de los Random Forests y el proceso iterativo.
- Requiere más recursos de memoria y tiempo que métodos más simples.
Casos de Uso: Es la elección preferida cuando la calidad de la imputación es primordial y se trabaja con datasets complejos donde las relaciones entre variables son intrincadas o no lineales.
Ejemplo de Código (Titanic – combinando numéricas y categóricas para imputación):
# Para MissForest, utilizaremos la librería 'missforest'.
# Si no la tienen instalada, pueden hacerlo con: pip install missingpy
# Aunque missingpy es una implementación popular, la base de IterativeImputer con RandomForestRegressor
# logra un efecto similar. Para simplicidad y porque está en scikit-learn, usaremos IterativeImputer
# con RandomForestRegressor como estimador, que es el espíritu de MissForest.
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import LabelEncoder
# Preparar el dataset Titanic para MissForest-like imputation
# Seleccionaremos 'Age', 'Fare', 'Embarked', 'Sex'
df_titanic_mf = df_titanic[['Age', 'Fare', 'Embarked', 'Sex']].copy()
# Convertir 'Sex' y 'Embarked' a numérico para el imputador
# Primero, rellenar NaN en 'Embarked' con la moda temporalmente para el LabelEncoder
df_titanic_mf['Embarked'].fillna(df_titanic_mf['Embarked'].mode()[0], inplace=True)
le_sex = LabelEncoder()
le_embarked = LabelEncoder()
df_titanic_mf['Sex_encoded'] = le_sex.fit_transform(df_titanic_mf['Sex'])
df_titanic_mf['Embarked_encoded'] = le_embarked.fit_transform(df_titanic_mf['Embarked'])
# Columnas a imputar
columns_to_impute_mf = ['Age', 'Fare', 'Sex_encoded', 'Embarked_encoded']
df_mf_impute = df_titanic_mf[columns_to_impute_mf].copy()
# Reintroducir NaN en 'Age' si se habían limpiado y 'Embarked' si se quiere imputar
df_mf_impute['Age'] = df_titanic[['Age']].copy() # Usamos la columna original con NaNs para Age
df_mf_impute['Embarked_encoded'] = df_titanic[['Embarked']].copy().fillna(np.nan) # Vuelvo a poner NaNs en Embarked
# Imputador iterativo con RandomForestRegressor
mf_imputer = IterativeImputer(RandomForestRegressor(random_state=0), max_iter=10, random_state=0)
df_mf_imputed = pd.DataFrame(mf_imputer.fit_transform(df_mf_impute), columns=columns_to_impute_mf)
print("\nValores faltantes en Titanic (Age, Embarked) después de MissForest-like Imputer:")
print(df_mf_imputed.isnull().sum())
# Decodificar 'Sex_encoded' y 'Embarked_encoded' de vuelta a sus valores originales si es necesario
df_mf_imputed['Sex'] = le_sex.inverse_transform(df_mf_imputed['Sex_encoded'].round().astype(int))
df_mf_imputed['Embarked'] = le_embarked.inverse_transform(df_mf_imputed['Embarked_encoded'].round().astype(int))
# Visualización de la distribución de 'Age' antes y después
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.histplot(df_titanic_mf['Age'].dropna(), kde=True)
plt.title('Distribución de Edad (Antes de MissForest)')
plt.subplot(1, 2, 2)
sns.histplot(df_mf_imputed['Age'], kde=True, color='red')
plt.title('Distribución de Edad (Después de MissForest)')
plt.tight_layout()
plt.show()Conclusiones: Eligiendo la Técnica Correcta y Evaluando la Imputación
Hemos recorrido un camino fascinante, desde la comprensión de la naturaleza de los datos faltantes hasta la implementación de técnicas de imputación avanzadas. Cada método —KNN Imputer, Iterative Imputer (MICE) y MissForest— tiene sus fortalezas y debilidades, y la elección del “mejor” dependerá en gran medida de las características específicas de tu dataset y los objetivos de tu análisis.
- KNN Imputer: Es una excelente opción cuando las relaciones locales entre los puntos de datos son importantes. Es relativamente sencillo de entender y aplicar, pero su rendimiento puede degradarse con la dimensionalidad o el tamaño del dataset, y es crucial escalar los datos.
- Iterative Imputer (MICE): Ofrece una imputación más sofisticada al modelar cada variable faltante en función de las demás. Su flexibilidad radica en la elección del estimador subyacente, lo que lo hace adaptable a diversos escenarios. Es una mejora significativa sobre los métodos de imputación univariados.
- MissForest: Al utilizar Random Forests, MissForest se destaca por su capacidad para manejar relaciones no lineales y diferentes tipos de datos sin suposiciones sobre su distribución. Produce imputaciones de muy alta calidad, pero a cambio, es el más computacionalmente intensivo.
¿Cuándo utilizar cada una?
- Para problemas con un volumen moderado de datos faltantes y la necesidad de capturar patrones locales, KNN Imputer es un buen punto de partida.
- Si buscas una imputación multivariada más robusta y tienes la capacidad de experimentar con diferentes modelos para la imputación, Iterative Imputer es tu aliado.
- Cuando la precisión de la imputación es crítica, la estructura de los datos es compleja (no linealidades, interacciones), y el tiempo de cómputo no es una limitación severa, MissForest (o Iterative Imputer con
RandomForestRegressor) es la opción más potente.
Evaluando la Calidad de la Imputación:
La evaluación de la imputación no es tan sencilla como medir la precisión de un modelo predictivo, ya que los “verdaderos” valores faltantes son, por definición, desconocidos. Sin embargo, podemos seguir varias estrategias:
- Análisis de Distribuciones: Comparar las distribuciones de las variables antes (solo datos observados) y después de la imputación. Idealmente, la distribución de los datos imputados debería ser similar a la de los datos observados de la misma variable.
- Impacto en el Modelo de Machine Learning: La métrica definitiva suele ser cómo afecta la imputación al rendimiento de su modelo downstream de Machine Learning. Entrena un modelo con los datos originales (sin faltantes o con imputación básica) y otro con los datos imputados con la técnica avanzada. Compara métricas como la precisión, F1-score, RMSE, etc.
- Análisis de Sensibilidad: Realizar imputaciones con diferentes técnicas y observar cuán estables son los resultados de su análisis o modelo.
- Visualización de Patrones de Faltantes: Herramientas como
missingnoen Python pueden ayudar a visualizar patrones de valores faltantes y cómo la imputación los ha rellenado.
En resumen, la imputación avanzada de datos faltantes es una habilidad esencial en el arsenal de cualquier científico de datos. Nos permite no solo manejar la ausencia de información, sino también extraer el máximo valor de nuestros datos, construyendo modelos más robustos, precisos y, en última instancia, más confiables. ¡Así que la próxima vez que te encuentres con un dataset lleno de “NaNs”, recuerda que tienes herramientas poderosas a tu disposición!
Recuerda que siempre siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.