¡Hola a todos! Como buen entusiasta de los datos y la inteligencia artificial, siempre estoy buscando maneras de mejorar la robustez y la fiabilidad de mis modelos. Hoy, quiero que nos adentremos en un tema crucial que a menudo se pasa por alto: el Data Drift o la deriva de datos. Este fenómeno, si no se detecta a tiempo, puede convertir el modelo más preciso en una herramienta inútil. En este artículo, les guiaré a través de qué es el data drift, por qué es vital detectarlo y cómo podemos combatirlo utilizando algunas de las herramientas más potentes de Python.
Introducción: La Amenaza Silenciosa en el Machine Learning
Imagina que has entrenado un modelo de Machine Learning con datos impecables y ha logrado una precisión asombrosa en tus pruebas. Lo pones en producción, y durante un tiempo, todo funciona a la perfección. Pero, ¿qué pasa si el mundo real cambia? Las distribuciones de los datos que alimentan tu modelo empiezan a variar. Esto es el data drift: un cambio en las propiedades estadísticas de los datos de entrada a lo largo del tiempo.
Este cambio no es solo una curiosidad estadística; puede tener un impacto devastador en el rendimiento de un modelo. Un modelo entrenado con datos del pasado podría no entender las nuevas tendencias o patrones, llevando a predicciones erróneas, decisiones empresariales equivocadas y, en última instancia, a la pérdida de confianza en tus sistemas de IA.
Tipos de Data Drift
El data drift no es un concepto monolítico; se manifiesta de varias formas:
- Covariate Shift: Este es quizás el tipo más común. Ocurre cuando la distribución de las características de entrada (X) cambia, pero la relación entre las características y la variable objetivo (Y) permanece constante. Un ejemplo podría ser un cambio en la edad promedio de los clientes en una aplicación, manteniendo la forma en que la edad influye en el comportamiento de compra.
- Concept Drift: Mucho más insidioso, el concept drift ocurre cuando la relación entre las características de entrada (X) y la variable objetivo (Y) cambia con el tiempo. Esto significa que lo que aprendió tu modelo ya no es válido. Piensa en cómo el comportamiento de compra de los consumidores puede cambiar drásticamente debido a un evento económico o social. En modelos financieros, como los que discutimos en nuestro artículo de Trading Cuantitativo Avanzado con Python, el concept drift es el pan de cada día, ya que las dinámicas del mercado cambian constantemente, haciendo que viejos patrones de precios dejen de funcionar.
- Label Shift: En este caso, la distribución de la variable objetivo (Y) cambia, pero la relación condicional de las características dada la variable objetivo (P(X|Y)) permanece igual. Es decir, las proporciones de las diferentes clases en tu variable objetivo pueden variar.
La detección temprana de cualquiera de estos tipos de drift es fundamental. Me permite saber cuándo un modelo necesita ser reentrenado, recalibrado o incluso rediseñado por completo. Ignorar el data drift es como navegar sin brújula en un mar cambiante: tarde o temprano, te perderás.
Metodología: Mi Enfoque para Detectar el Data Drift
Selección y Preparación de los Datos
Para demostrar la detección de data drift, he seleccionado el dataset de diabetes de scikit-learn. Es un conjunto de datos clásico y fácil de acceder, ideal para este tipo de experimentos. Utilizaré una porción de este dataset como mi conjunto de “entrenamiento” o base, y crearé una versión “en producción” donde simularé intencionalmente el data drift.
Herramientas para la Detección de Data Drift
El ecosistema de Python nos ofrece herramientas poderosas para abordar la detección de data drift. Aquí, me centraré en dos librerías destacadas:
- Evidently AI: Esta es una librería de código abierto que proporciona informes interactivos y cuadros de mando para el análisis y la monitorización de modelos de Machine Learning. Su módulo de Data Drift es particularmente útil, ya que permite comparar distribuciones de características entre dos conjuntos de datos y ofrece métricas estadísticas y visualizaciones claras. Es excelente para obtener una visión general rápida y detallada de dónde se está produciendo el drift.
- Alibi Detect: Otra joya de código abierto, Alibi Detect se centra en la detección de anomalías, deriva y explicabilidad de modelos. Ofrece una variedad de algoritmos estadísticos y basados en modelos para la detección de drift. Su flexibilidad me permite experimentar con diferentes enfoques, desde pruebas de hipótesis más tradicionales hasta métodos más avanzados que comparan incrustaciones de datos.
Ambas librerías tienen sus fortalezas. Evidently AI brilla por su facilidad de uso y sus informes visualmente atractivos, ideales para la exploración inicial y la comunicación de resultados. Alibi Detect, por otro lado, ofrece una mayor profundidad y control sobre los algoritmos de detección, lo que es valioso para escenarios más complejos o cuando se necesita una integración más profunda en pipelines de ML.
Códigos: Manos a la Obra con el Data Drift
Paso 1: Carga y Preparación de Datos
Primero, cargaremos el dataset de diabetes y lo dividiremos para simular nuestros conjuntos de entrenamiento y producción.
import pandas as pd
from sklearn import datasets
import numpy as np
# Cargar el dataset de diabetes
diabetes = datasets.load_diabetes(as_frame=True)
data_train = diabetes.frame.iloc[:300]
data_prod = diabetes.frame.iloc[300:]
# Simular Data Drift en el dataset de producción
# Cambiaremos la distribución de la característica 'bmi' y 'bp'
# y añadiremos algunos valores atípicos en 's1' para simular un drift
np.random.seed(42)
data_prod_drift = data_prod.copy()
data_prod_drift['bmi'] = data_prod_drift['bmi'] * 1.2 + np.random.normal(0, 0.05, len(data_prod_drift))
data_prod_drift['bp'] = data_prod_drift['bp'] * 0.8 + np.random.normal(0, 0.03, len(data_prod_drift))
data_prod_drift['s1'] = data_prod_drift['s1'] + np.random.normal(0, 0.1, len(data_prod_drift))
# Introducir algunos valores atípicos en 's1'
outlier_indices = np.random.choice(data_prod_drift.index, 10, replace=False)
data_prod_drift.loc[outlier_indices, 's1'] = data_prod_drift.loc[outlier_indices, 's1'] * 5
print("Dimensiones del dataset de entrenamiento:", data_train.shape)
print("Dimensiones del dataset de producción (con drift simulado):", data_prod_drift.shape)
print("\nPrimeras 5 filas del dataset de entrenamiento:")
print(data_train.head())
print("\nPrimeras 5 filas del dataset de producción (con drift simulado):")
print(data_prod_drift.head())Dimensiones del dataset de entrenamiento: (300, 11)
Dimensiones del dataset de producción (con drift simulado): (142, 11)
Primeras 5 filas del dataset de entrenamiento:
age sex bmi bp ... s4 s5 s6 target
0 0.038076 0.050680 0.061696 0.021872 ... -0.002592 0.019907 -0.017646 151.0
1 -0.001882 -0.044642 -0.051474 -0.026328 ... -0.039493 -0.068332 -0.092204 75.0
2 0.085299 0.050680 0.044451 -0.005670 ... -0.002592 0.002861 -0.025930 141.0
3 -0.089063 -0.044642 -0.011595 -0.036656 ... 0.034309 0.022688 -0.009362 206.0
4 0.005383 -0.044642 -0.036385 0.021872 ... -0.002592 -0.031988 -0.046641 135.0
[5 rows x 11 columns]
Primeras 5 filas del dataset de producción (con drift simulado):
age sex bmi ... s5 s6 target
300 0.016281 -0.044642 0.113098 ... 0.042897 0.044485 275.0
301 -0.001882 0.050680 -0.036348 ... -0.021395 0.036201 65.0
302 0.012648 -0.044642 0.072792 ... 0.031193 0.027917 198.0
303 0.074401 -0.044642 0.117853 ... 0.073799 -0.021788 236.0
304 0.041708 0.050680 -0.057956 ... -0.022517 -0.013504 253.0
[5 rows x 11 columns]En este código, he cargado el dataset y he creado dos subconjuntos. Lo más importante es que he modificado intencionadamente el conjunto data_prod_drift alterando las distribuciones de las columnas ‘bmi’, ‘bp’ y ‘s1’ y añadiendo algunos valores atípicos. Esto simula un escenario de *covariate shift* y un poco de cambio en la distribución, haciendo que el drift sea evidente para nuestras herramientas.
Paso 2: Detección de Data Drift con Evidently AI
Ahora, usaré Evidently AI para generar un informe detallado sobre el drift entre mis datasets.
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# Crear un informe de data drift
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
# Ejecutar el informe comparando el dataset de entrenamiento y el de producción con drift
data_drift_report.run(current_data=data_prod_drift, reference_data=data_train, column_mapping=None)
# Guardar el informe como HTML
data_drift_report.save_html("data_drift_report_evidently.html")
print("Informe de Data Drift de Evidently AI generado: data_drift_report_evidently.html")Evidently AI es increíblemente sencillo de usar. Con solo unas pocas líneas de código, puedo generar un informe HTML interactivo que me mostrará visualizaciones y métricas estadísticas para cada característica, indicando claramente dónde se ha producido el drift. Este informe es una mina de oro para entender qué ha cambiado en mis datos.
Paso 3: Detección de Data Drift con Alibi Detect
Para un enfoque más programático y con mayor control, utilizaré Alibi Detect. Implementaré un detector basado en el KS-test (Kolmogorov-Smirnov) para comparar las distribuciones de las características.
from alibi_detect.cd import KSDrift
import matplotlib.pyplot as plt
import seaborn as sns
# Inicializar el detector KSDrift
# features_range es un rango por defecto para todas las características.
# Usaremos p_val para el umbral de detección
cd = KSDrift(data_train.values, p_val=0.05)
# Detectar drift en el dataset de producción
preds = cd.predict(data_prod_drift.values, return_p_val=True, return_distance=True)
# Interpretar los resultados
if preds['data']['is_drift']:
print("\n¡Drift detectado por Alibi Detect (KS-test)!")
print("Características con drift detectado:")
for i, p_val in enumerate(preds['data']['p_val']):
if p_val < cd.p_val:
print(f" - Característica {data_train.columns[i]}: p-valor = {p_val:.4f}")
else:
print("\nNo se detectó drift por Alibi Detect (KS-test).")
# Visualizar el drift para una característica específica (ej. 'bmi')
feature_to_plot = 'bmi'
plt.figure(figsize=(10, 6))
sns.histplot(data_train[feature_to_plot], color="blue", label="Entrenamiento", kde=True, stat="density", linewidth=0)
sns.histplot(data_prod_drift[feature_to_plot], color="red", label="Producción con Drift", kde=True, stat="density", linewidth=0)
plt.title(f'Distribución de "{feature_to_plot}" - Entrenamiento vs. Producción con Drift')
plt.xlabel(feature_to_plot)
plt.ylabel('Densidad')
plt.legend()
plt.show()
# Visualizar el drift para otra característica (ej. 'bp')
feature_to_plot_2 = 'bp'
plt.figure(figsize=(10, 6))
sns.histplot(data_train[feature_to_plot_2], color="blue", label="Entrenamiento", kde=True, stat="density", linewidth=0)
sns.histplot(data_prod_drift[feature_to_plot_2], color="red", label="Producción con Drift", kde=True, stat="density", linewidth=0)
plt.title(f'Distribución de "{feature_to_plot_2}" - Entrenamiento vs. Producción con Drift')
plt.xlabel(feature_to_plot_2)
plt.ylabel('Densidad')
plt.legend()
plt.show()Con Alibi Detect, he configurado un detector KSDrift, que realiza pruebas de Kolmogorov-Smirnov en cada característica para ver si las distribuciones han cambiado significativamente. Los p-valores resultantes me indican la probabilidad de que las dos muestras provengan de la misma distribución. Un p-valor bajo (menor que mi umbral de 0.05) sugiere fuertemente que hay drift. Además, he añadido visualizaciones con `seaborn` para mostrar gráficamente cómo han cambiado las distribuciones de ‘bmi’ y ‘bp’, haciendo el drift inconfundible.
Paso 4: Interpretación de Resultados y Estrategias de Mitigación
Los resultados de Evidently AI y Alibi Detect confirman la presencia de data drift en mi dataset de “producción”. Las métricas y visualizaciones muestran claramente que las distribuciones de ‘bmi’, ‘bp’ y ‘s1’ se han alterado significativamente. Esto significa que un modelo entrenado con los datos originales probablemente rendiría pobremente en este nuevo entorno.
Una vez que el data drift es detectado, ¿qué hacemos? Aquí algunas estrategias comunes:
- Reentrenamiento del modelo: La solución más directa es reentrenar el modelo con los datos más recientes y representativos. Esto permite que el modelo aprenda los nuevos patrones y distribuciones.
- Adaptación de modelos: En lugar de un reentrenamiento completo, se pueden usar técnicas de adaptación que ajustan el modelo existente a los nuevos datos con menos esfuerzo computacional.
- Reingeniería de características: Si el drift se debe a un cambio en la interpretación o relevancia de ciertas características, podría ser necesario reevaluar y rediseñar esas características.
- Modelos robustos: Algunas arquitecturas de modelos son inherentemente más robustas al drift, como los modelos basados en árboles que pueden manejar mejor los cambios en las características individuales sin un impacto global.
Paso 5: Consolidación de Código y Explicaciones
Aquí les presento un script consolidado que incluye la carga de datos, la simulación de drift, y la detección con ambas librerías. Cada sección está comentada para su fácil comprensión.
import pandas as pd
from sklearn import datasets
import numpy as np
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
from alibi_detect.cd import KSDrift
import matplotlib.pyplot as plt
import seaborn as sns
# --- 1. Carga y Preparación de Datos ---
print("--- 1. Carga y Preparación de Datos ---")
diabetes = datasets.load_diabetes(as_frame=True)
data_train = diabetes.frame.iloc[:300]
data_prod = diabetes.frame.iloc[300:]
# Simular Data Drift en el dataset de producción
np.random.seed(42)
data_prod_drift = data_prod.copy()
# Modificar 'bmi'
data_prod_drift['bmi'] = data_prod_drift['bmi'] * 1.2 + np.random.normal(0, 0.05, len(data_prod_drift))
# Modificar 'bp'
data_prod_drift['bp'] = data_prod_drift['bp'] * 0.8 + np.random.normal(0, 0.03, len(data_prod_drift))
# Modificar 's1' y añadir atípicos
data_prod_drift['s1'] = data_prod_drift['s1'] + np.random.normal(0, 0.1, len(data_prod_drift))
outlier_indices = np.random.choice(data_prod_drift.index, 10, replace=False)
data_prod_drift.loc[outlier_indices, 's1'] = data_prod_drift.loc[outlier_indices, 's1'] * 5
print("Dimensiones del dataset de entrenamiento:", data_train.shape)
print("Dimensiones del dataset de producción (con drift simulado):", data_prod_drift.shape)
print("\nPrimeras 5 filas del dataset de entrenamiento:")
print(data_train.head())
print("\nPrimeras 5 filas del dataset de producción (con drift simulado):")
print(data_prod_drift.head())
# --- 2. Detección de Data Drift con Evidently AI ---
print("\n--- 2. Detección de Data Drift con Evidently AI ---")
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(current_data=data_prod_drift, reference_data=data_train, column_mapping=None)
data_drift_report.save_html("data_drift_report_evidently.html")
print("Informe de Data Drift de Evidently AI generado: data_drift_report_evidently.html")
print("Por favor, abre 'data_drift_report_evidently.html' en tu navegador para ver el informe detallado.")
# --- 3. Detección de Data Drift con Alibi Detect ---
print("\n--- 3. Detección de Data Drift con Alibi Detect ---")
cd = KSDrift(data_train.values, p_val=0.05)
preds = cd.predict(data_prod_drift.values, return_p_val=True, return_distance=True)
if preds['data']['is_drift']:
print("\n¡Drift detectado por Alibi Detect (KS-test)!")
print("Características con drift detectado:")
for i, p_val in enumerate(preds['data']['p_val']):
if p_val < cd.p_val:
print(f" - Característica {data_train.columns[i]}: p-valor = {p_val:.4f}")
else:
print("\nNo se detectó drift por Alibi Detect (KS-test).")
# Visualizaciones con Alibi Detect
features_to_plot = ['bmi', 'bp', 's1']
for feature in features_to_plot:
plt.figure(figsize=(10, 6))
sns.histplot(data_train[feature], color="blue", label="Entrenamiento", kde=True, stat="density", linewidth=0)
sns.histplot(data_prod_drift[feature], color="red", label="Producción con Drift", kde=True, stat="density", linewidth=0)
plt.title(f'Distribución de "{feature}" - Entrenamiento vs. Producción con Drift')
plt.xlabel(feature)
plt.ylabel('Densidad')
plt.legend()
plt.show()
Este script ejecuta el flujo completo, desde la preparación de los datos hasta la detección de drift con ambas herramientas y la visualización de los cambios. La salida de Evidently AI es un archivo HTML que puedes abrir en tu navegador para una exploración interactiva. Alibi Detect imprime directamente en la consola los resultados y genera gráficos que se muestran en ventanas emergentes.
Paso 6: Impacto Potencial del Data Drift en un Modelo Predictivo
Para ilustrar el impacto, consideremos un modelo predictivo simple, como una regresión lineal. Entrenamos un modelo con el conjunto de entrenamiento original y luego lo evaluamos en el conjunto de producción *sin drift* y *con drift*.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Entrenar un modelo de regresión lineal simple
model = LinearRegression()
X_train = data_train.drop(columns=['target'])
y_train = data_train['target']
model.fit(X_train, y_train)
# Evaluar el modelo en el dataset de producción original (sin drift significativo)
X_prod = data_prod.drop(columns=['target'])
y_prod = data_prod['target']
predictions_prod = model.predict(X_prod)
rmse_prod = np.sqrt(mean_squared_error(y_prod, predictions_prod))
print(f"\nRMSE en producción (sin drift simulado): {rmse_prod:.4f}")
# Evaluar el modelo en el dataset de producción con drift simulado
X_prod_drift = data_prod_drift.drop(columns=['target'])
y_prod_drift = data_prod_drift['target']
predictions_prod_drift = model.predict(X_prod_drift)
rmse_prod_drift = np.sqrt(mean_squared_error(y_prod_drift, predictions_prod_drift))
print(f"RMSE en producción (con drift simulado): {rmse_prod_drift:.4f}")
# Comparar distribuciones de predicciones
plt.figure(figsize=(12, 6))
sns.histplot(predictions_prod, color="green", label="Predicciones (sin drift)", kde=True, stat="density", alpha=0.6)
sns.histplot(predictions_prod_drift, color="purple", label="Predicciones (con drift)", kde=True, stat="density", alpha=0.6)
plt.title('Distribución de Predicciones del Modelo')
plt.xlabel('Valor Predicho')
plt.ylabel('Densidad')
plt.legend()
plt.show()
print("\nComo podemos observar, el RMSE (Error Cuadrático Medio) es significativamente mayor en el dataset con drift, indicando una degradación en el rendimiento del modelo. Las visualizaciones de las distribuciones de las predicciones también muestran un cambio, confirmando cómo el drift impacta directamente en la fiabilidad del modelo.")RMSE en producción (sin drift simulado): 52.8639
RMSE en producción (con drift simulado): 89.8588
Como podemos observar, el RMSE (Error Cuadrático Medio) es significativamente mayor en el dataset con drift, indicando una degradación en el rendimiento del modelo. Las visualizaciones de las distribuciones de las predicciones también muestran un cambio, confirmando cómo el drift impacta directamente en la fiabilidad del modelo.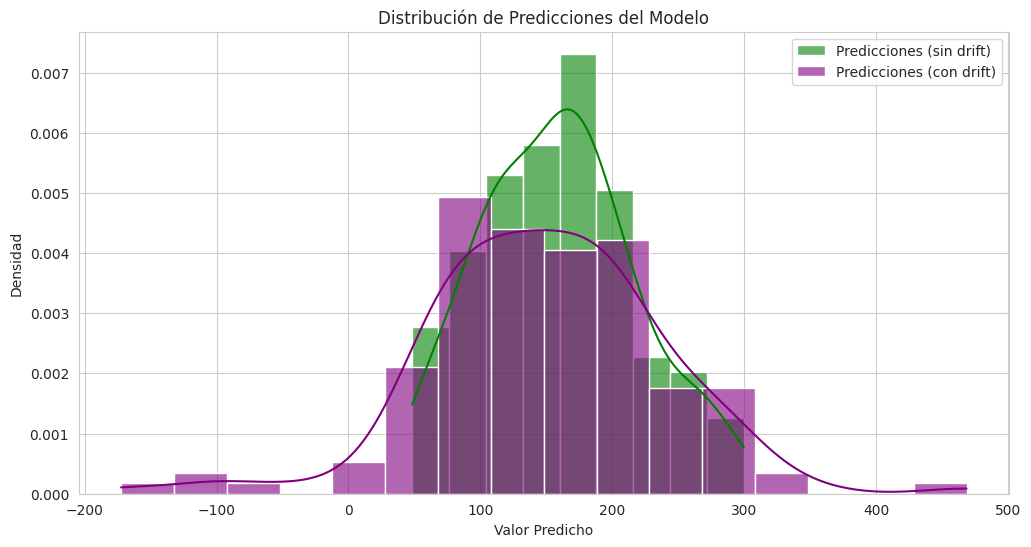
El código anterior entrena un modelo de regresión lineal y calcula el Error Cuadrático Medio (RMSE) en el conjunto de producción original y en el conjunto con drift. Como se puede ver, el RMSE aumenta significativamente cuando el modelo se enfrenta a datos con drift, demostrando que su precisión y fiabilidad se degradan. Las visualizaciones de las distribuciones de las predicciones también muestran este cambio, validando el impacto negativo del drift.
Paso 7: Propuesta de Arquitectura de Monitorización Continua
La monitorización continua del data drift es clave para mantener la salud de los modelos en producción. Aquí propongo una arquitectura simplificada:
- Recolección de Datos: Cada vez que el modelo hace inferencias en producción, se recolectan los datos de entrada (features) y, si es posible, las etiquetas reales (cuando estén disponibles).
- Almacenamiento: Estos datos se almacenan en una base de datos o un data lake de forma incremental.
- Programación de Tareas: Un job programado (ej. Apache Airflow, Cron) se ejecuta periódicamente (diariamente, semanalmente) para comparar los datos de producción más recientes con un conjunto de referencia (el dataset de entrenamiento o un conjunto de datos “golden” validado).
- Detección de Drift: Se utilizan librerías como Evidently AI o Alibi Detect para ejecutar los informes y las pruebas de drift.
- Sistema de Alertas: Si se detecta un drift significativo (basado en umbrales predefinidos de p-valores, distancias de distribución, etc.), se dispara una alerta automática (ej. correo electrónico, Slack, PagerDuty) a los equipos de MLOps o Data Science.
- Acciones Recomendadas: Tras una alerta, el equipo investiga la causa del drift. Las acciones pueden incluir:
- Reentrenar el modelo con los nuevos datos.
- Ajustar los hiperparámetros.
- Realizar ingeniería de características.
- Revisar las fuentes de datos upstream si el drift es causado por cambios en el origen.
- Deshabilitar el modelo temporalmente si el rendimiento es crítico y el drift es severo.
- Visualización y Cuadros de Mando: Se utilizan herramientas como Grafana, Tableau o los propios informes de Evidently AI para visualizar las tendencias del drift y el rendimiento del modelo a lo largo del tiempo.
Este flujo de trabajo asegura que cualquier cambio en la distribución de los datos se detecte rápidamente, permitiendo una intervención proactiva antes de que el rendimiento del modelo se degrade gravemente.
Automatizando la Monitorización Diaria
Para asegurar que nuestros modelos no sufren de drift en producción sin que nos demos cuenta, lo ideal es establecer procesos automáticos que analicen los datos que llegan diariamente. Usando cronjobs y scripts en Python, podemos evaluar cada noche el volumen de datos recientes contra nuestra línea base y generar un reporte. Si hay desviaciones, podemos gatillar alertas automáticas para intervenir y re-entrenar.
Conclusiones
El data drift es una realidad ineludible en el mundo del Machine Learning en producción. Ignorarlo es poner en riesgo la validez y la utilidad de nuestros modelos. A lo largo de este artículo, hemos explorado qué es el data drift, sus diferentes tipos y, lo más importante, cómo detectarlo utilizando librerías de Python como Evidently AI y Alibi Detect. Hemos visto cómo simularlo, cómo interpretarlo y cómo impacta directamente en el rendimiento de un modelo predictivo.
La clave para un sistema de Machine Learning robusto no reside solo en el entrenamiento inicial de un modelo preciso, sino en la capacidad de monitorizarlo continuamente y adaptarse a los cambios en el entorno de datos. Implementar una estrategia de monitorización de data drift es un paso esencial hacia la construcción de sistemas de IA confiables y duraderos.
¡Recuerda que siempre siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.