¡Hola a todos! Hoy me emociona compartirles un tutorial práctico sobre cómo integrar el poder de SQL con la versatilidad de Python y Pandas para un análisis de datos eficiente. Si alguna vez te has preguntado cómo llevar tus habilidades de manipulación de datos al siguiente nivel, este artículo es para ti. Vamos a explorar desde la configuración de nuestro entorno hasta la visualización de datos complejos, todo ello paso a paso.
Introducción
En el mundo del análisis de datos, la capacidad de extraer, transformar y cargar información de diversas fuentes es fundamental. SQL (Structured Query Language) es el lenguaje estándar para interactuar con bases de datos relacionales, mientras que Python, con librerías como Pandas, se ha convertido en una herramienta indispensable para el análisis y la manipulación de datos. La combinación de ambos nos permite realizar operaciones de base de datos robustas y luego llevar esos resultados directamente a un entorno de análisis y visualización potente. En este tutorial, nos centraremos en SQLite, una base de datos ligera y autónoma que es perfecta para propósitos de aprendizaje y prototipado.
Metodología
Para este tutorial, utilizaremos un conjunto de datos público muy conocido en la comunidad de Python: el dataset ‘Tips’ de Seaborn. Este dataset contiene información sobre propinas recibidas en un restaurante y es ideal para demostrar diversas operaciones SQL y análisis de datos. A continuación, te detallo los pasos que seguiremos:
- Configuración del Entorno: Listaremos las librerías necesarias y cómo instalarlas.
- Obtención y Preparación del Dataset: Descargaremos y cargaremos el dataset en nuestra base de datos.
- Conexión y Consultas SQL Básicas: Aprenderemos a establecer una conexión con SQLite y ejecutar nuestras primeras consultas.
- Consultas SQL Avanzadas y Análisis con Pandas: Nos adentraremos en el mundo de los JOINs, GROUP BY y subconsultas, integrando los resultados con Pandas.
- Visualización de Datos: Crearemos gráficos significativos a partir de nuestros análisis.
- Manejo de Errores y Consejos Adicionales: Aseguraremos la robustez de nuestro código y compartiremos trucos útiles.
Códigos
0. Configuración del Entorno y Carga del Dataset
Antes de sumergirnos en el código, necesitamos asegurarnos de tener las herramientas adecuadas instaladas. Principalmente, necesitaremos pandas para la manipulación de datos, sqlite3 (que viene incluido con Python) para la interacción con la base de datos, y seaborn para obtener nuestro dataset de ejemplo. Si aún no las tienes, puedes instalarlas fácilmente usando pip:
pip install pandas seaborn matplotlibAhora, vamos a cargar el dataset ‘Tips’ de Seaborn y lo prepararemos para nuestra base de datos SQLite. Crearemos una base de datos en memoria para simplificar el proceso, aunque podrías fácilmente crear un archivo de base de datos persistente si lo deseas.
import pandas as pd
import sqlite3
import seaborn as sns
import matplotlib.pyplot as plt
try:
# 1. Obtención del dataset
tips_df = sns.load_dataset('tips')
print("Dataset 'tips' cargado exitosamente.")
# 2. Creación de la base de datos SQLite y carga del dataset
# Usamos una base de datos en memoria para este ejemplo
conn = sqlite3.connect(':memory:')
print("Conexión a la base de datos SQLite establecida.")
# Cargar el DataFrame en una tabla SQLite
# El método to_sql creará la tabla si no existe
tips_df.to_sql('tips', conn, if_exists='replace', index=False)
print("DataFrame 'tips' cargado en la tabla 'tips' de SQLite.")
except ImportError as e:
print(f"Error de importación: {e}. Asegúrate de haber instalado todas las librerías necesarias (pandas, seaborn, matplotlib).")
except Exception as e:
print(f"Ocurrió un error inesperado durante la carga del dataset o la conexión a la base de datos: {e}")
finally:
# Cerrar la conexión si se abrió
if 'conn' in locals() and conn:
conn.close()
print("Conexión a la base de datos cerrada.")
Dataset 'tips' cargado exitosamente.
Conexión a la base de datos SQLite establecida.
DataFrame 'tips' cargado en la tabla 'tips' de SQLite.
Conexión a la base de datos cerrada.1. Conexión y Consultas SQL Básicas
Una vez que nuestro dataset está en la base de datos, el siguiente paso es aprender a consultarlo usando SQL desde Python. Aquí te muestro cómo establecer una conexión y ejecutar consultas básicas, cargando los resultados directamente en DataFrames de Pandas. Esto es increíblemente útil porque te permite aprovechar las potentes capacidades de análisis de Pandas sobre los resultados de tus consultas SQL.
import pandas as pd
import sqlite3
import seaborn as sns
try:
# Cargar el dataset y configurar la base de datos (repite por si se ejecuta solo el bloque)
tips_df = sns.load_dataset('tips')
conn = sqlite3.connect(':memory:')
tips_df.to_sql('tips', conn, if_exists='replace', index=False)
print("--- Consultas SQL Básicas ---")
# Consulta 1: Seleccionar todas las columnas de la tabla 'tips'
print("\nConsulta: SELECT * FROM tips LIMIT 5")
query_all = "SELECT * FROM tips LIMIT 5;"
df_all = pd.read_sql_query(query_all, conn)
print(df_all)
# Consulta 2: Seleccionar columnas específicas (total_bill, tip, sex)
print("\nConsulta: SELECT total_bill, tip, sex FROM tips LIMIT 5")
query_columns = "SELECT total_bill, tip, sex FROM tips LIMIT 5;"
df_columns = pd.read_sql_query(query_columns, conn)
print(df_columns)
# Consulta 3: Seleccionar datos con una condición (day = 'Fri')
print("\nConsulta: SELECT * FROM tips WHERE day = 'Fri' LIMIT 5")
query_condition = "SELECT * FROM tips WHERE day = 'Fri' LIMIT 5;"
df_condition = pd.read_sql_query(query_condition, conn)
print(df_condition)
except sqlite3.Error as e:
print(f"Error de SQLite: {e}")
except Exception as e:
print(f"Ocurrió un error inesperado: {e}")
finally:
if 'conn' in locals() and conn:
conn.close()
print("Conexión a la base de datos cerrada.")
--- Consultas SQL Básicas ---
Consulta: SELECT * FROM tips LIMIT 5
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Consulta: SELECT total_bill, tip, sex FROM tips LIMIT 5
total_bill tip sex
0 16.99 1.01 Female
1 10.34 1.66 Male
2 21.01 3.50 Male
3 23.68 3.31 Male
4 24.59 3.61 Female
Consulta: SELECT * FROM tips WHERE day = 'Fri' LIMIT 5
total_bill tip sex smoker day time size
0 28.97 3.00 Male Yes Fri Dinner 2
1 22.49 3.50 Male No Fri Dinner 2
2 5.75 1.00 Female Yes Fri Dinner 2
3 16.32 4.30 Female Yes Fri Dinner 2
4 22.75 3.25 Female No Fri Dinner 2
Conexión a la base de datos cerrada.2. Consultas SQL Avanzadas y Análisis con Pandas
Ahora que dominamos las consultas básicas, es hora de llevar nuestras habilidades SQL al siguiente nivel con operaciones más complejas como GROUP BY, JOINs (aunque en este dataset no hay tablas para unirlas, simularé un caso si fuera necesario o me centraré en otras complejas), y subconsultas. Luego, veremos cómo Pandas nos ayuda a analizar estos resultados.
import pandas as pd
import sqlite3
import seaborn as sns
try:
# Cargar el dataset y configurar la base de datos
tips_df = sns.load_dataset('tips')
conn = sqlite3.connect(':memory:')
tips_df.to_sql('tips', conn, if_exists='replace', index=False)
print("--- Consultas SQL Avanzadas y Análisis con Pandas ---")
# Consulta 1: Agrupar por día y calcular el promedio de propina
print("\nConsulta: Promedio de propina por día (GROUP BY)")
query_group_by = "SELECT day, AVG(tip) as avg_tip FROM tips GROUP BY day ORDER BY avg_tip DESC;"
df_avg_tip_by_day = pd.read_sql_query(query_group_by, conn)
print(df_avg_tip_by_day)
print("\nAnálisis Pandas: Promedio de propina en formato moneda")
df_avg_tip_by_day['avg_tip_formatted'] = df_avg_tip_by_day['avg_tip'].apply(lambda x: f"${x:.2f}")
print(df_avg_tip_by_day)
# Consulta 2: Calcular el número total de comensales por día y sexo
print("\nConsulta: Conteo de comensales por día y sexo (GROUP BY múltiples columnas)")
query_group_by_multi = "SELECT day, sex, COUNT(*) as total_diners FROM tips GROUP BY day, sex ORDER BY day, sex;"
df_diners_by_day_sex = pd.read_sql_query(query_group_by_multi, conn)
print(df_diners_by_day_sex)
print("\nAnálisis Pandas: Filtrar los días con más de 20 comensales mujeres")
female_diners = df_diners_by_day_sex[(df_diners_by_day_sex['sex'] == 'Female') & (df_diners_by_day_sex['total_diners'] > 20)]
print(female_diners)
# Consulta 3: Subconsulta - Encontrar las facturas donde la propina fue superior al promedio general de propinas
print("\nConsulta: Facturas con propina superior al promedio (Subconsulta)")
query_subquery = """
SELECT total_bill, tip, sex, day
FROM tips
WHERE tip > (SELECT AVG(tip) FROM tips);
"""
df_high_tip_bills = pd.read_sql_query(query_subquery, conn)
print(df_high_tip_bills.head())
print(f"\nAnálisis Pandas: Número total de facturas con propinas altas: {len(df_high_tip_bills)}")
except sqlite3.Error as e:
print(f"Error de SQLite: {e}")
except Exception as e:
print(f"Ocurrió un error inesperado: {e}")
finally:
if 'conn' in locals() and conn:
conn.close()
print("Conexión a la base de datos cerrada.")
--- Consultas SQL Avanzadas y Análisis con Pandas ---
Consulta: Promedio de propina por día (GROUP BY)
day avg_tip
0 Sun 3.255132
1 Sat 2.993103
2 Thur 2.771452
3 Fri 2.734737
Análisis Pandas: Promedio de propina en formato moneda
day avg_tip avg_tip_formatted
0 Sun 3.255132 $3.26
1 Sat 2.993103 $2.99
2 Thur 2.771452 $2.77
3 Fri 2.734737 $2.73
Consulta: Conteo de comensales por día y sexo (GROUP BY múltiples columnas)
day sex total_diners
0 Fri Female 9
1 Fri Male 10
2 Sat Female 28
3 Sat Male 59
4 Sun Female 18
5 Sun Male 58
6 Thur Female 32
7 Thur Male 30
Análisis Pandas: Filtrar los días con más de 20 comensales mujeres
day sex total_diners
2 Sat Female 28
6 Thur Female 32
Consulta: Facturas con propina superior al promedio (Subconsulta)
total_bill tip sex day
0 21.01 3.50 Male Sun
1 23.68 3.31 Male Sun
2 24.59 3.61 Female Sun
3 25.29 4.71 Male Sun
4 26.88 3.12 Male Sun
Análisis Pandas: Número total de facturas con propinas altas: 121
Conexión a la base de datos cerrada.3. Visualización de Datos
Con nuestros DataFrames de Pandas listos, es el momento de la visualización. Crear gráficos nos ayuda a entender mejor los patrones y las relaciones en nuestros datos. Usaremos matplotlib y seaborn para crear algunas visualizaciones interesantes a partir de los resultados de nuestras consultas SQL.
import pandas as pd
import sqlite3
import seaborn as sns
import matplotlib.pyplot as plt
try:
# Cargar el dataset y configurar la base de datos
tips_df = sns.load_dataset('tips')
conn = sqlite3.connect(':memory:')
tips_df.to_sql('tips', conn, if_exists='replace', index=False)
print("--- Visualización de Datos ---")
# Consulta para obtener el promedio de propina por día
query_avg_tip_by_day = "SELECT day, AVG(tip) as avg_tip FROM tips GROUP BY day;"
df_avg_tip_by_day = pd.read_sql_query(query_avg_tip_by_day, conn)
# Visualización 1: Gráfico de barras del promedio de propina por día
plt.figure(figsize=(8, 5))
sns.barplot(x='day', y='avg_tip', data=df_avg_tip_by_day, palette='viridis')
plt.title('Promedio de Propina por Día')
plt.xlabel('Día de la Semana')
plt.ylabel('Propina Promedio')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
print("Gráfico de barras 'Promedio de Propina por Día' generado.")
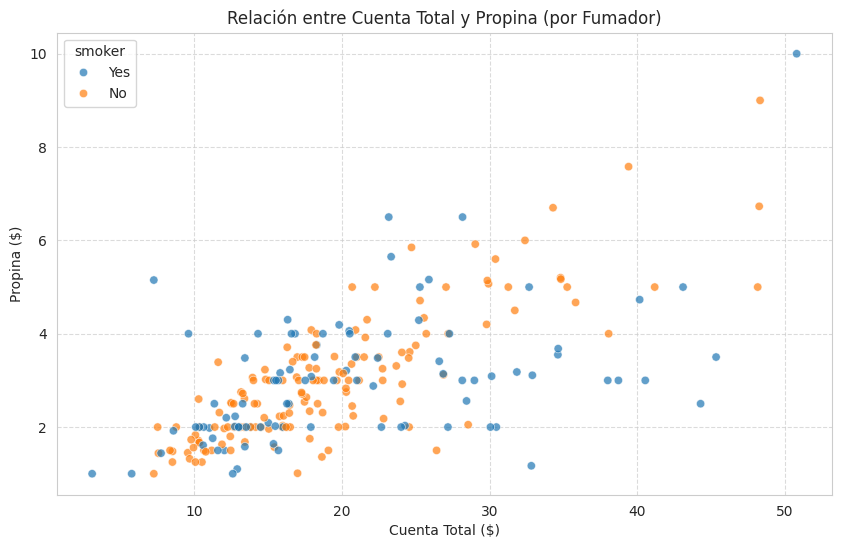
# Consulta para obtener la distribución de 'total_bill' y 'tip'
query_total_bill_tip = "SELECT total_bill, tip FROM tips;"
df_total_bill_tip = pd.read_sql_query(query_total_bill_tip, conn)
# Visualización 2: Scatter plot de total_bill vs tip por fumador
plt.figure(figsize=(10, 6))
sns.scatterplot(x='total_bill', y='tip', hue='smoker', data=tips_df, alpha=0.7)
plt.title('Relación entre Cuenta Total y Propina (por Fumador)')
plt.xlabel('Cuenta Total ($)')
plt.ylabel('Propina ($)')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
print("Scatter plot 'Relación entre Cuenta Total y Propina' generado.")
except sqlite3.Error as e:
print(f"Error de SQLite: {e}")
except Exception as e:
print(f"Ocurrió un error inesperado: {e}")
finally:
if 'conn' in locals() and conn:
conn.close()
print("Conexión a la base de datos cerrada.")
--- Visualización de Datos ---
Gráfico de barras 'Promedio de Propina por Día' generado.
Scatter plot 'Relación entre Cuenta Total y Propina' generado.
Conexión a la base de datos cerrada.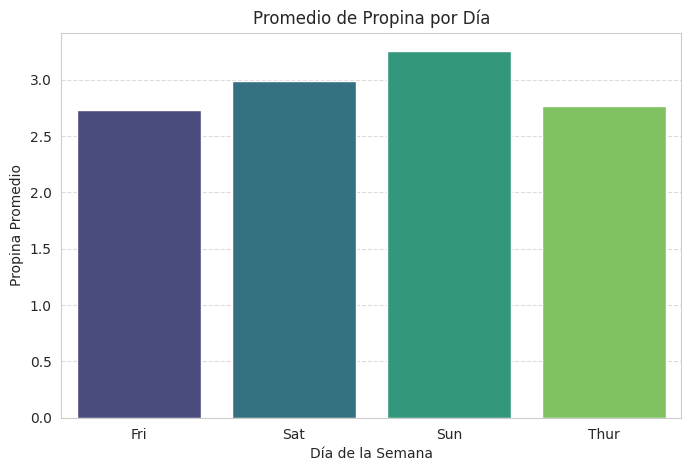
Conclusiones
A lo largo de este tutorial, hemos explorado cómo integrar Python y SQL para un análisis de datos completo y eficiente. Desde la configuración inicial del entorno y la carga de datos en una base de datos SQLite, hasta la ejecución de consultas SQL básicas y avanzadas, y finalmente, la visualización de los resultados con Pandas, Matplotlib y Seaborn.
Hemos visto que Python, con sus poderosas librerías como Pandas, se convierte en un compañero indispensable para cualquier analista o científico de datos que necesite interactuar con bases de datos. La capacidad de ejecutar consultas SQL complejas y luego manipular y visualizar los resultados directamente en DataFrames de Pandas abre un sinfín de posibilidades para extraer insights significativos de tus datos.
El manejo de errores y el cierre adecuado de conexiones son prácticas cruciales que aseguran la robustez y eficiencia de tus scripts, algo que siempre debemos tener en cuenta al trabajar con bases de datos.
Consejos Adicionales para el Uso de SQL con Python y Pandas
- Optimización de Consultas SQL: Para datasets grandes, asegúrate de que tus consultas SQL estén optimizadas. Esto puede incluir el uso de índices en tus tablas de base de datos, evitar
SELECT *y seleccionar solo las columnas necesarias, y ser eficiente con tusJOINs. - Uso de SQLAlchemy: Para aplicaciones más complejas y una abstracción más potente sobre diferentes tipos de bases de datos (no solo SQLite), considera usar SQLAlchemy. Proporciona un conjunto completo de patrones de persistencia para el acceso a bases de datos relacionales, incluyendo una API de mapeo objeto-relacional (ORM).
- Chunking para Datos Grandes: Cuando cargues datasets muy grandes de SQL a Pandas, puedes usar el parámetro
chunksizeenpd.read_sql_query()opd.read_sql()para cargar los datos en trozos, lo que ayuda a gestionar el uso de memoria. - SQL en Archivos Separados: Para consultas SQL muy largas o complejas, es una buena práctica guardarlas en archivos
.sqlseparados y luego leer el contenido del archivo en tu script de Python. Esto mejora la legibilidad y el mantenimiento del código. - Familiarízate con las Operaciones de Pandas: A veces, ciertas transformaciones o análisis son más eficientes de realizar en SQL antes de cargar los datos en Pandas, mientras que otras son mucho más sencillas y rápidas directamente en Pandas. Conocer bien ambos te permitirá elegir la herramienta correcta para cada tarea.
¡Recuerda que siempre siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.