¡Hola a todos! Como su redactor y entusiasta de la automatización, hoy les traigo un artículo que considero fundamental para cualquiera que esté inmerso en el mundo del análisis de datos. Mi objetivo es guiarlos a través de los pasos clave para automatizar sus flujos de trabajo de análisis de datos usando Python. La automatización no es solo una palabra de moda; es una necesidad que nos permite ser más eficientes, reducir errores y liberar tiempo valioso para tareas más estratégicas.
Introducción: La Necesidad de Automatizar
En mi experiencia, uno de los mayores desafíos en el análisis de datos es la repetición de tareas. Desde la limpieza y transformación de datos hasta la generación de reportes, muchas de estas actividades son recurrentes y, si se hacen manualmente, consumen una cantidad de tiempo considerable. Aquí es donde la automatización entra en juego. Al automatizar estos procesos, no solo gano en eficiencia, sino que también aseguro la consistencia y reduzco la probabilidad de errores humanos. En este artículo, les mostraré cómo pueden empezar a automatizar sus propias tareas, sentando las bases para flujos de trabajo de datos más robustos y escalables.
Metodología: Preparando el Terreno
Investigación y Selección de Datasets
Para ilustrar los conceptos de este artículo, he seleccionado dos datasets públicos y muy accesibles de la librería seaborn: tips e iris. Estos datasets son perfectos para demostrar tareas comunes de limpieza, transformación y análisis, ya que son lo suficientemente pequeños para ser manejables, pero lo suficientemente complejos para presentar situaciones reales.
import seaborn as sns
# Cargar el dataset 'tips'
tips_df = sns.load_dataset('tips')
print("Dataset 'tips' cargado exitosamente. Primeras 5 filas:")
print(tips_df.head())
# Cargar el dataset 'iris'
iris_df = sns.load_dataset('iris')
print("\nDataset 'iris' cargado exitosamente. Primeras 5 filas:")
print(iris_df.head())Dataset 'tips' cargado exitosamente. Primeras 5 filas:
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Dataset 'iris' cargado exitosamente. Primeras 5 filas:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaPreparación del Entorno y Control de Versiones
Antes de sumergirnos en el código, es crucial tener un entorno de desarrollo bien configurado. Siempre recomiendo usar entornos virtuales de Python (venv) para aislar las dependencias de nuestros proyectos. Además, el control de versiones con Git es indispensable para gestionar nuestro código y colaborar eficientemente.
# Crear un entorno virtual (en la terminal)
# python -m venv mi_entorno_automatizacion
# Activar el entorno virtual (Linux/macOS)
# source mi_entorno_automatizacion/bin/activate
# Activar el entorno virtual (Windows)
# mi_entorno_automatizacion\Scripts\activate
# Instalar librerías esenciales
# pip install pandas numpy matplotlib seaborn scikit-learn
# Inicializar un repositorio Git (en la raíz de tu proyecto)
# git init
# git add .
# git commit -m "Initial commit for automation project"Códigos: Automatizando el Análisis de Datos
Librerías Esenciales y Manipulación de Datos
pandas y numpy son mis caballos de batalla para la manipulación y análisis de datos en Python. Aquí les muestro ejemplos prácticos utilizando el dataset tips, demostrando limpieza básica, filtrado y agrupación.
import pandas as pd
import numpy as np
import seaborn as sns
tips_df = sns.load_dataset('tips')
# 1. Limpieza de datos: Manejo de valores nulos (aunque 'tips' no tiene nulos, es una buena práctica)
print("Valores nulos antes de la limpieza:")
print(tips_df.isnull().sum())
# En caso de tener nulos, podría ser:
# tips_df_cleaned = tips_df.dropna() # Eliminar filas con nulos
# tips_df_filled = tips_df.fillna(tips_df.mean(numeric_only=True)) # Rellenar con la media
# 2. Filtrado de datos: Seleccionar propinas mayores a 5 dólares
large_tips = tips_df[tips_df['tip'] > 5]
print("\nPropinas mayores a 5 dólares:")
print(large_tips.head())
# 3. Agrupación y agregación: Promedio de propina por día de la semana
tip_by_day = tips_df.groupby('day')['tip'].mean().reset_index()
print("\nPromedio de propina por día de la semana:")
print(tip_by_day)
# 4. Transformación de datos: Crear una nueva columna 'tip_percentage'
tips_df['tip_percentage'] = (tips_df['tip'] / tips_df['total_bill']) * 100
print("\nDataset con 'tip_percentage':")
print(tips_df.head())Valores nulos antes de la limpieza:
total_bill 0
tip 0
sex 0
smoker 0
day 0
time 0
size 0
dtype: int64
Propinas mayores a 5 dólares:
total_bill tip sex smoker day time size
23 39.42 7.58 Male No Sat Dinner 4
44 30.40 5.60 Male No Sun Dinner 4
47 32.40 6.00 Male No Sun Dinner 4
52 34.81 5.20 Female No Sun Dinner 4
59 48.27 6.73 Male No Sat Dinner 4
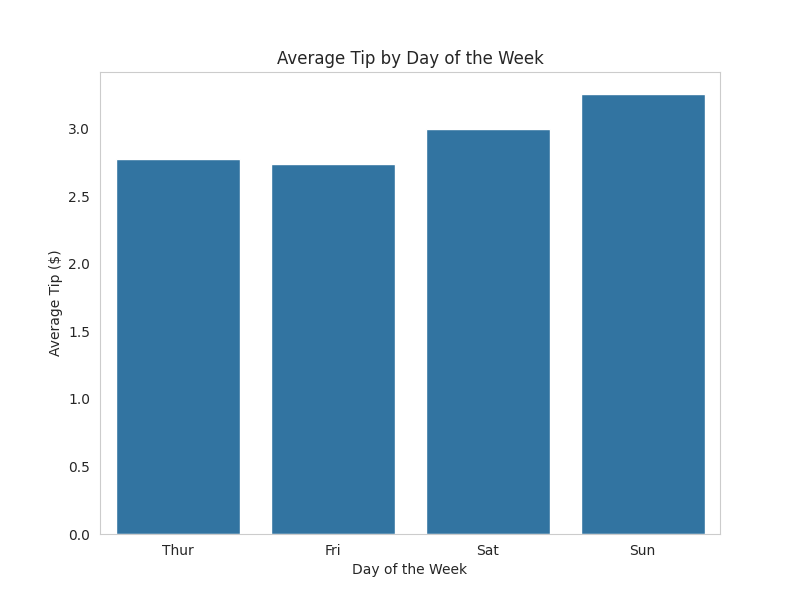
Promedio de propina por día de la semana:
day tip
0 Thur 2.771452
1 Fri 2.734737
2 Sat 2.993103
3 Sun 3.255132
Dataset con 'tip_percentage':
total_bill tip sex smoker day time size tip_percentage
0 16.99 1.01 Female No Sun Dinner 2 5.944673
1 10.34 1.66 Male No Sun Dinner 3 16.054159
2 21.01 3.50 Male No Sun Dinner 3 16.658734
3 23.68 3.31 Male No Sun Dinner 2 13.978041
4 24.59 3.61 Female No Sun Dinner 4 14.680765Visualización de Datos y Generación de Reportes
Una vez que los datos están limpios y transformados, la visualización es clave para comunicar hallazgos. matplotlib y seaborn son excelentes para esto. Además, les mostraré cómo podrían automatizar la generación de un reporte básico.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
tips_df = sns.load_dataset('tips')
# Crear un gráfico de dispersión de 'total_bill' vs 'tip'
plt.figure(figsize=(8, 6))
sns.scatterplot(x='total_bill', y='tip', hue='smoker', data=tips_df)
plt.title('Total Bill vs Tip by Smoker Status')
plt.xlabel('Total Bill ($)')
plt.ylabel('Tip ($)')
plt.grid(True)
plt.savefig('tip_vs_bill_scatterplot.png') # Guardar el gráfico
plt.close() # Cerrar la figura para no mostrarla en línea
print("Gráfico 'tip_vs_bill_scatterplot.png' generado exitosamente.")
# Crear un gráfico de barras del promedio de propina por día
plt.figure(figsize=(8, 6))
sns.barplot(x='day', y='tip', data=tips_df, estimator=np.mean, errorbar=None)
plt.title('Average Tip by Day of the Week')
plt.xlabel('Day of the Week')
plt.ylabel('Average Tip ($)')
plt.grid(axis='y')
plt.savefig('average_tip_by_day.png') # Guardar el gráfico
plt.close()
print("Gráfico 'average_tip_by_day.png' generado exitosamente.")
# Simulación de generación de reporte simple (ej. a un archivo de texto o markdown)
report_content = """
# Reporte de Análisis de Propinas
## Resumen Ejecutivo
Este reporte analiza el dataset 'tips' para identificar patrones en las propinas.
## Hallazgos Clave
- Las propinas tienden a aumentar con la cuenta total.
- El día con el promedio de propina más alto es {}.
## Visualizaciones
- Ver 'tip_vs_bill_scatterplot.png'
- Ver 'average_tip_by_day.png'
""".format(tips_df.groupby('day')['tip'].mean().idxmax())
with open('reporte_propinas.md', 'w') as f:
f.write(report_content)
print("Reporte 'reporte_propinas.md' generado exitosamente.")Gráfico 'tip_vs_bill_scatterplot.png' generado exitosamente.
Gráfico 'average_tip_by_day.png' generado exitosamente.
Reporte 'reporte_propinas.md' generado exitosamente.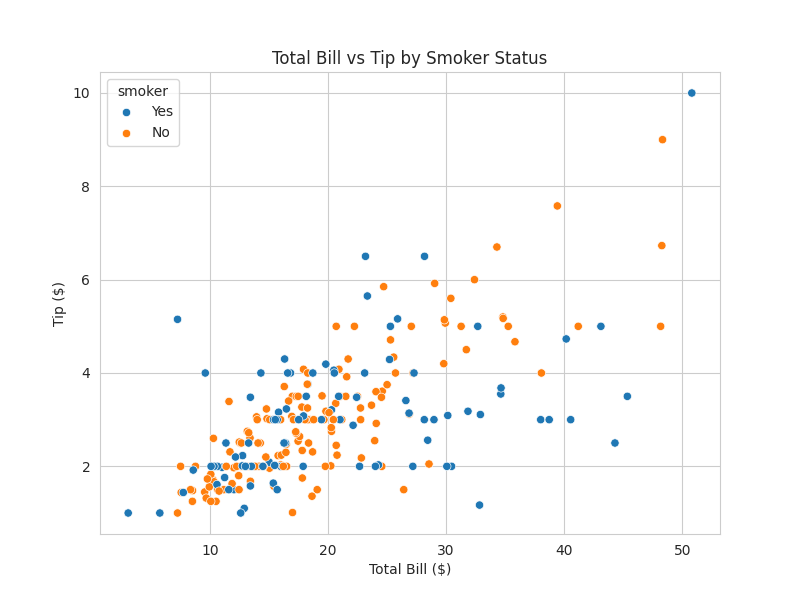
Automatización de Flujos de Trabajo y Orquestación Básica
La verdadera magia de la automatización es la capacidad de ejecutar scripts de forma programada y encadenar tareas. Aunque Python tiene librerías como schedule, para propósitos de este artículo, quiero mostrarles la idea básica de ejecutar un script de Python desde la línea de comandos, que es el fundamento de cualquier orquestación.
# Supongamos que tenemos un script llamado 'analisis_diario.py'
# que contiene el código de manipulación y visualización anterior.
# Contenido de 'analisis_diario.py':
# import pandas as pd
# import numpy as np
# import seaborn as sns
# import matplotlib.pyplot as plt
#
# tips_df = sns.load_dataset('tips')
#
# # Procesamiento de datos
# tip_by_day = tips_df.groupby('day')['tip'].mean().reset_index()
#
# # Generación de gráfico
# plt.figure(figsize=(8, 6))
# sns.barplot(x='day', y='tip', data=tip_by_day)
# plt.title('Average Tip by Day')
# plt.savefig('daily_tip_average.png')
# plt.close()
#
# print("Análisis diario completado y gráfico guardado.")
import subprocess
def run_analysis_script():
"""Ejecuta un script de análisis de datos."""
try:
# Asegúrate de que 'python' se refiere a tu entorno virtual si estás en uno.
# En producción, usarías la ruta completa al ejecutable de Python del venv.
result = subprocess.run(['python', 'analisis_diario.py'], capture_output=True, text=True, check=True)
print("Script ejecutado con éxito:")
print(result.stdout)
except subprocess.CalledProcessError as e:
print(f"Error al ejecutar el script: {e}")
print(f"Stderr: {e.stderr}")
except FileNotFoundError:
print("Error: 'analisis_diario.py' no encontrado. Asegúrate de que el archivo existe.")
# Para ejecutar este código, necesitarías crear primero el archivo 'analisis_diario.py'
# run_analysis_script()
print("La función 'run_analysis_script' está definida. Para ejecutarla, necesitarías el archivo 'analisis_diario.py'.")
print("Ejecución manual en terminal para simular:")
print("python analisis_diario.py")La función 'run_analysis_script' está definida. Para ejecutarla, necesitarías el archivo 'analisis_diario.py'.
Ejecución manual en terminal para simular:
python analisis_diario.pyPara una orquestación más avanzada, pueden explorar librerías como schedule para tareas simples basadas en tiempo dentro de un script Python, o herramientas del sistema operativo como cron en Linux/macOS y el Programador de Tareas en Windows para programar la ejecución de sus scripts.
Pruebas y Depuración de Scripts
La robustez de nuestros flujos de trabajo automatizados depende de que nuestros scripts funcionen correctamente bajo diversas condiciones. Siempre recomiendo añadir bloques try-except para el manejo de errores y realizar pruebas exhaustivas. Imprimir mensajes en la consola (como he hecho en los ejemplos) es una forma sencilla de depuración, pero para proyectos más complejos, las herramientas de depuración de IDEs como VS Code o PyCharm son invaluable.
import pandas as pd
import seaborn as sns
def process_data_safely(df_name):
"""
Intenta cargar y procesar un dataset, manejando posibles errores.
"""
try:
df = sns.load_dataset(df_name)
print(f"Dataset '{df_name}' cargado exitosamente.")
# Simulación de un procesamiento que podría fallar
if 'total_bill' in df.columns:
average_bill = df['total_bill'].mean()
print(f"Promedio de 'total_bill': {average_bill:.2f}")
else:
raise ValueError(f"La columna 'total_bill' no se encontró en el dataset '{df_name}'.")
print(f"Procesamiento de '{df_name}' completado.")
return df
except ValueError as ve:
print(f"Error de valor durante el procesamiento de '{df_name}': {ve}")
return None
except Exception as e:
print(f"Ocurrió un error inesperado al procesar '{df_name}': {e}")
return None
# Ejemplo de uso con un dataset existente
processed_tips = process_data_safely('tips')
if processed_tips is not None:
print("Dataset 'tips' procesado con éxito y listo para continuar.")
# Ejemplo de uso con un dataset que no existe (simulación de error)
# processed_non_existent = process_data_safely('non_existent_dataset')
print("\nPara probar el manejo de errores, intenta llamar a 'process_data_safely' con un nombre de dataset incorrecto.")Dataset 'tips' cargado exitosamente.
Promedio de 'total_bill': 19.79
Procesamiento de 'tips' completado.
Dataset 'tips' procesado con éxito y listo para continuar.
Para probar el manejo de errores, intenta llamar a 'process_data_safely' con un nombre de dataset incorrecto.Conclusiones: El Futuro Automatizado de tu Análisis
Hemos recorrido un camino fascinante, desde la preparación del entorno hasta la manipulación de datos, visualización y los cimientos de la automatización. La capacidad de automatizar tareas repetitivas en el análisis de datos no es solo una habilidad técnica; es una mentalidad que impulsa la eficiencia y la innovación. Al dominar estas herramientas y conceptos, estoy convencido de que podrán transformar su forma de trabajar, pasando de ser reactivos a proactivos en sus proyectos de datos. Los animo a aplicar lo aprendido, experimentar con sus propios datasets y scripts, y construir flujos de trabajo que los liberen para enfocarse en la interpretación y la estrategia.
¡Y recuerda que siempre siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.