Análisis Exploratorio de Datos (EDA) con Pandas en Python: Desvelando Secretos de tus Datos
¡Hola a todos! Hoy quiero compartir con ustedes un pilar fundamental en el mundo de la ciencia de datos: el Análisis Exploratorio de Datos (EDA). Si alguna vez te has sentido abrumado por un conjunto de datos, sin saber por dónde empezar, el EDA es tu mejor amigo. Como yo lo veo, es el primer paso crucial para entender qué historias esconden tus datos, antes de sumergirnos en modelos complejos o predicciones.
En este artículo, me enfocaré en cómo realizo un EDA efectivo utilizando dos herramientas poderosas en Python: la librería Pandas para la manipulación de datos y algunas funciones básicas de visualización. Para que la explicación sea lo más clara posible, utilizaremos un conjunto de datos clásico y muy conocido: el famoso dataset de Iris.
Introducción
El Análisis Exploratorio de Datos, o EDA por sus siglas en inglés (Exploratory Data Analysis), es un enfoque para analizar conjuntos de datos y resumir sus características principales, a menudo con métodos visuales. Su objetivo principal es descubrir patrones, detectar anomalías, probar hipótesis y verificar suposiciones con la ayuda de estadísticas resumidas y representaciones gráficas. Personalmente, considero que el EDA es como un “reconocimiento” previo a cualquier batalla de modelado; te permite familiarizarte con el terreno y anticipar posibles desafíos.
Metodología
Mi metodología para realizar un EDA efectivo generalmente sigue una serie de pasos sistemáticos. Estos pasos me permiten obtener una comprensión profunda de los datos, identificar problemas potenciales y guiar las decisiones futuras en el proceso de análisis. Aquí te detallo los que seguiremos hoy:
- Carga del Dataset: Importar los datos a un entorno de Python utilizando Pandas.
- Inspección Básica de Datos: Obtener una primera vista de la estructura, tipo de datos y presencia de valores nulos.
- Estadísticas Descriptivas: Resumir las características numéricas del dataset.
- Análisis de Valores Únicos y Frecuencias: Entender la diversidad y distribución de las variables categóricas.
- Visualizaciones Preliminares: Crear gráficos simples para identificar relaciones, distribuciones y posibles atípicos.
Códigos
Ahora, manos a la obra. Les mostraré el código Python que utilizo para cada uno de los pasos mencionados. He agregado comentarios detallados para que puedan seguir mi razonamiento en cada línea.
1. Carga del Dataset
Para comenzar, necesitamos cargar el conjunto de datos. En este caso, utilizaremos el dataset de Iris que ya viene preinstalado en scikit-learn, una librería muy popular en machine learning. Luego, lo convertiremos a un DataFrame de Pandas para facilitar su manipulación.
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
# Cargar el dataset de Iris
iris = load_iris()
# Convertir a DataFrame de Pandas
df_iris = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# Añadir la columna de la clase (species)
df_iris['species'] = iris.target_names[iris.target]
print("Dataset cargado correctamente.")Dataset cargado correctamente.2. Inspección Básica de Datos
Una vez que tengo el dataset cargado, mi siguiente paso es siempre una inspección rápida para entender su forma, las primeras filas y los tipos de datos. Esto me da una idea general de qué esperar.
# Mostrar las primeras 5 filas del DataFrame
print("Primeras 5 filas del DataFrame:")
print(df_iris.head())
# Mostrar la información general del DataFrame (tipos de datos, no nulos)
print("
Información general del DataFrame:")
print(df_iris.info())
# Mostrar el tamaño del DataFrame (filas, columnas)
print("
Dimensiones del DataFrame (filas, columnas):")
print(df_iris.shape)3. Estadísticas Descriptivas
Para las columnas numéricas, es fundamental obtener un resumen estadístico. Esto me proporciona rápidamente medidas como la media, desviación estándar, valores mínimos y máximos, y los cuartiles, lo cual es invaluable para entender la distribución de las variables.
# Mostrar estadísticas descriptivas de las columnas numéricas
print("
Estadísticas descriptivas del DataFrame:")
print(df_iris.describe())4. Análisis de Valores Únicos y Frecuencias
Para las variables categóricas (como ‘species’ en este caso), me interesa saber cuántos valores únicos hay y la frecuencia de cada uno. Esto me ayuda a identificar posibles errores de entrada o desequilibrios en las clases.
# Contar valores únicos en la columna 'species'
print("
Conteo de valores únicos para la columna 'species':")
print(df_iris['species'].value_counts())
# Mostrar valores únicos en la columna 'species'
print("
Valores únicos en la columna 'species':")
print(df_iris['species'].unique())5. Visualizaciones Preliminares
Finalmente, la parte visual. Un gráfico vale más que mil palabras, y en EDA, esto es especialmente cierto. Aquí les muestro cómo genero algunos gráficos básicos para visualizar las distribuciones y relaciones.
Histogramas para distribución de características
# Histograma de todas las características numéricas
df_iris.hist(bins=15, figsize=(10, 8))
plt.suptitle('Distribución de Características del Dataset Iris', y=1.02)
plt.tight_layout(rect=[0, 0.03, 1, 0.98]) # Ajustar para que no se solapen los títulos
plt.show()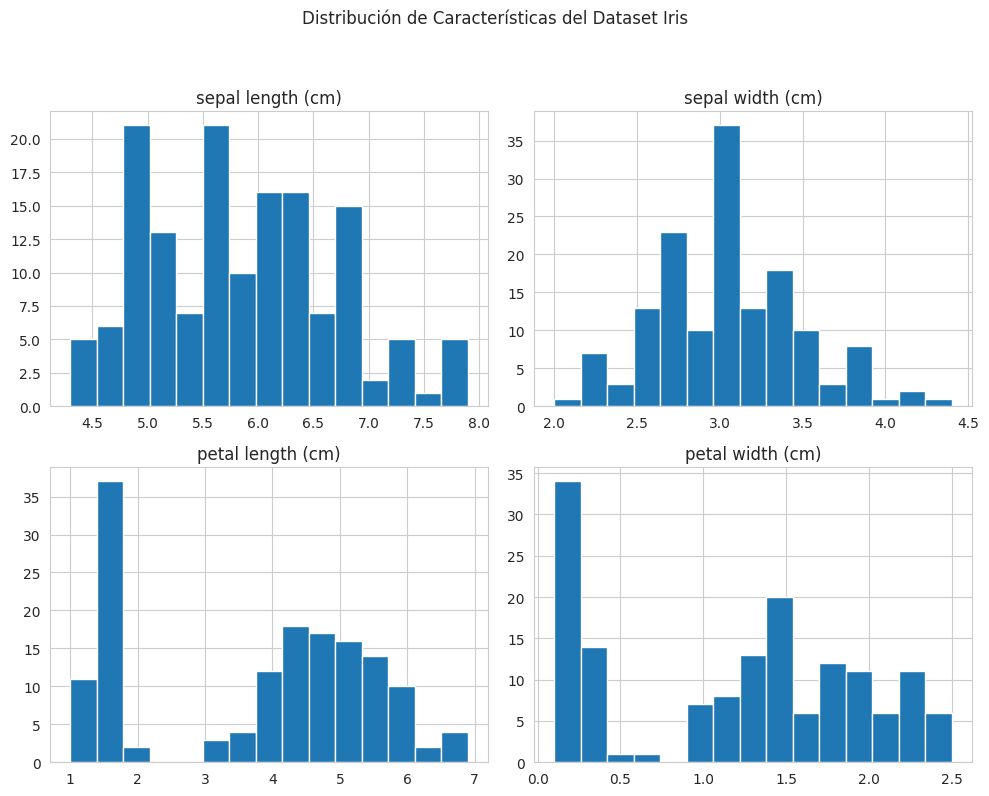
Scatter Plot para relaciones entre características
Un scatter plot me ayuda a ver cómo se relacionan dos variables numéricas, y si agrego el color por la categoría, puedo visualizar la separación de las clases.
# Scatter plot de 'sepal length (cm)' vs 'sepal width (cm)', coloreado por 'species'
sns.scatterplot(x='sepal length (cm)', y='sepal width (cm)', hue='species', data=df_iris)
plt.title('Longitud vs. Ancho del Sépalo por Especie')
plt.show()
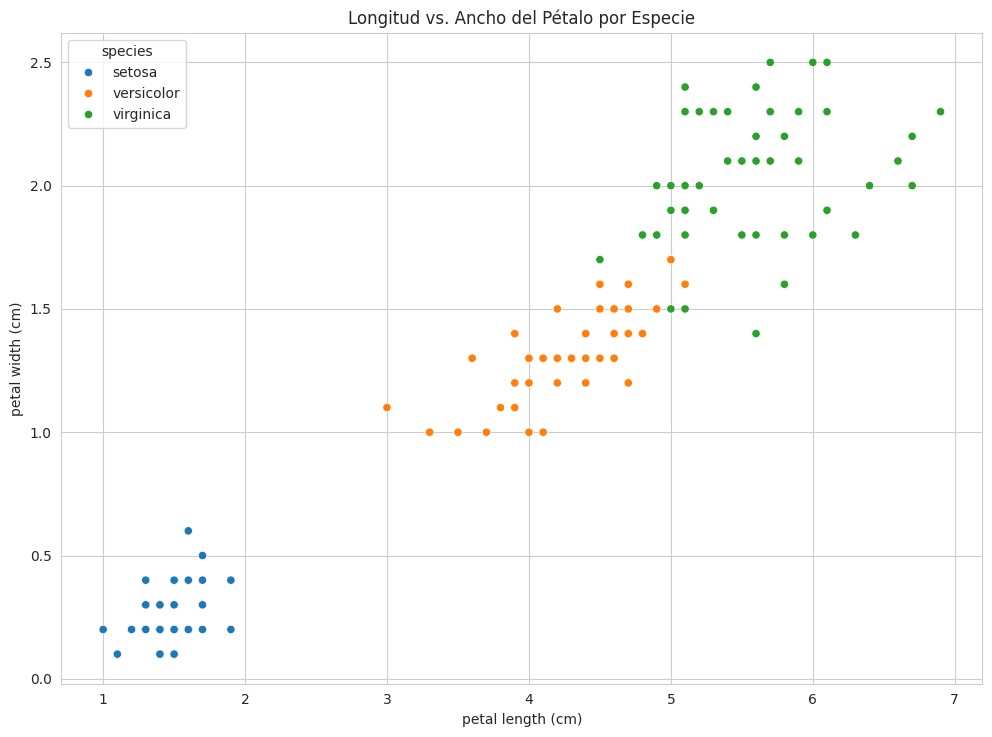
# Scatter plot de 'petal length (cm)' vs 'petal width (cm)', coloreado por 'species'
sns.scatterplot(x='petal length (cm)', y='petal width (cm)', hue='species', data=df_iris)
plt.title('Longitud vs. Ancho del Pétalo por Especie')
plt.show()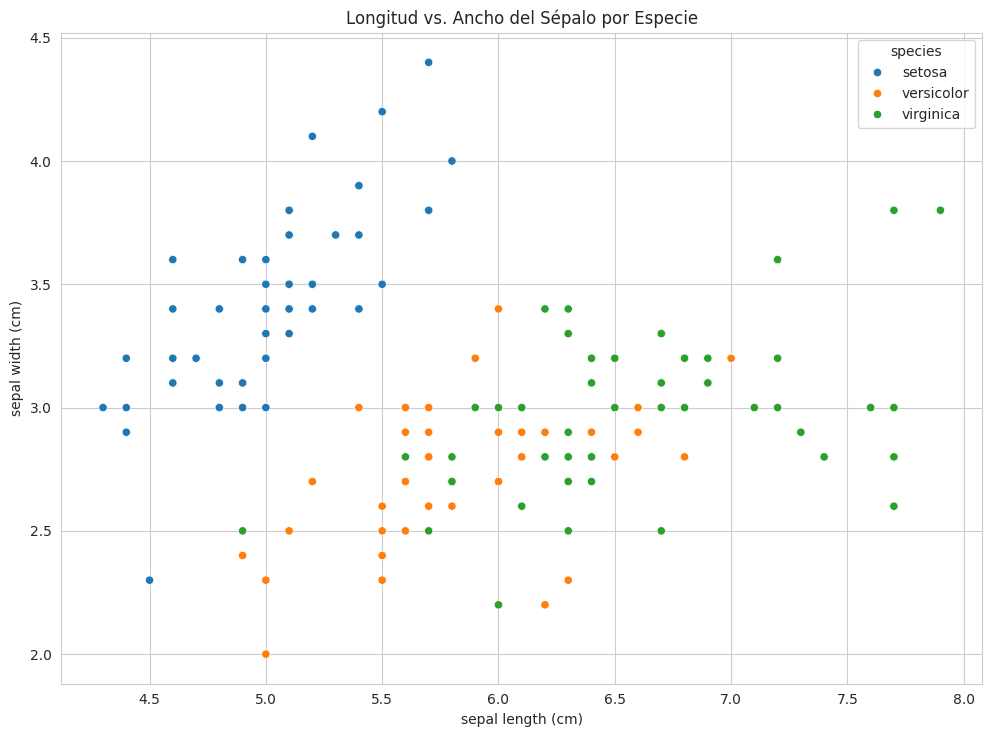
Box Plot para distribución y detección de outliers por categoría
Los box plots son excelentes para visualizar la distribución de una característica numérica a través de diferentes categorías y para identificar posibles valores atípicos.
# Box plot de 'sepal length (cm)' por 'species'
sns.boxplot(x='species', y='sepal length (cm)', data=df_iris)
plt.title('Distribución de Longitud del Sépalo por Especie')
plt.show()
# Box plot de 'petal length (cm)' por 'species'
sns.boxplot(x='species', y='petal length (cm)', data=df_iris)
plt.title('Distribución de Longitud del Pétalo por Especie')
plt.show()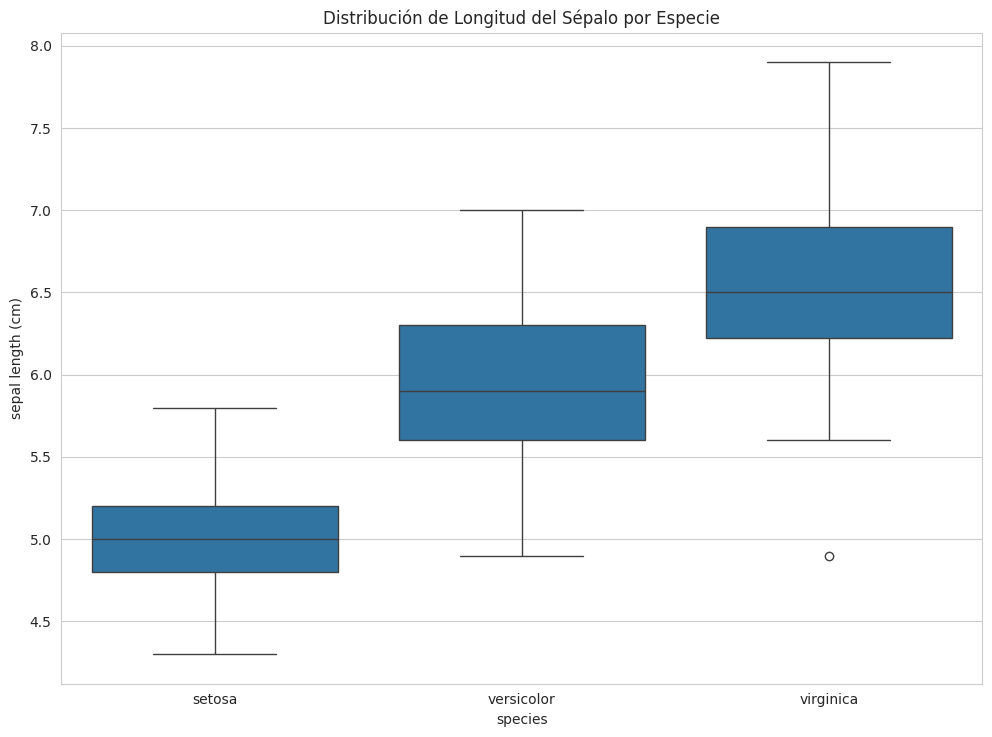
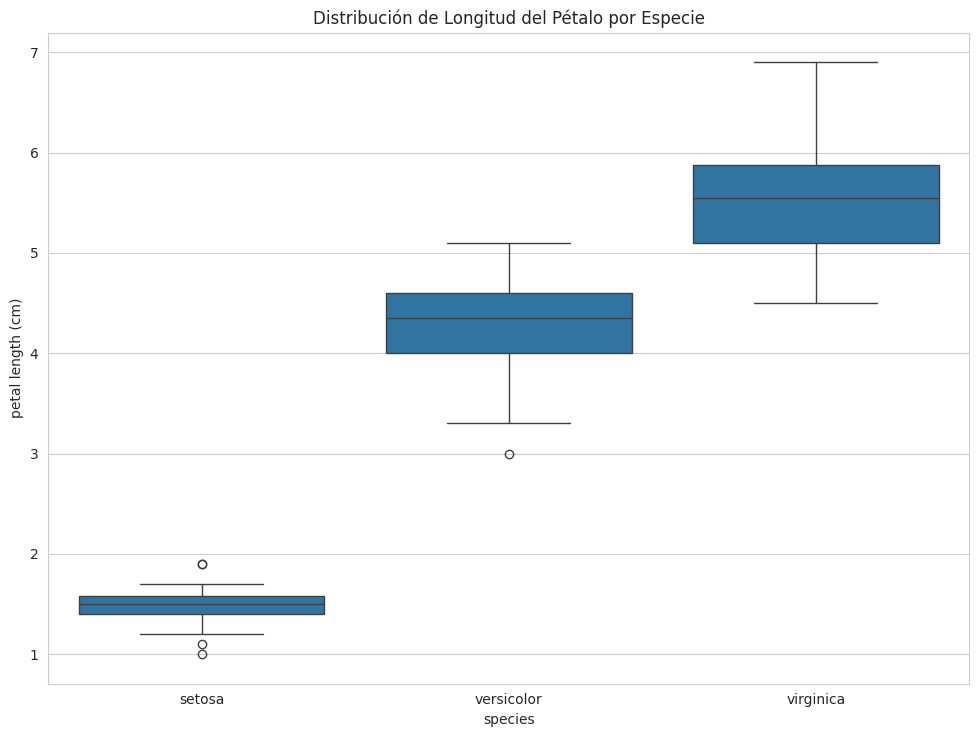
Conclusiones
A través de este Análisis Exploratorio de Datos con Pandas, he podido obtener una comprensión clara y rápida del dataset de Iris. He inspeccionado su estructura, resumido sus características principales, identificado la distribución de las especies y visualizado las relaciones entre sus atributos. Estos pasos iniciales son vitales; me permiten no solo familiarizarme con los datos, sino también detectar problemas, formular hipótesis y planificar los siguientes pasos de mi análisis o modelado.
El EDA no es un lujo, es una necesidad. Me proporciona la base sólida sobre la cual construir cualquier proyecto de ciencia de datos, asegurándome de que mis decisiones estén informadas por un conocimiento profundo de la información que tengo en mis manos.
¡Espero verte por ahí!
Y recuerda que siempre, siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.