¡Hola a todos! Como su redactor de confianza, me emociona presentarles esta guía completa para dar sus primeros pasos en el análisis de datos con Python. A lo largo de este artículo, he destilado mi experiencia para ofrecerles un camino claro y práctico, centrado en construir un portafolio de proyectos que realmente impresione.
Introducción: Tu Viaje en el Análisis de Datos Comienza Aquí
El análisis de datos se ha convertido en una habilidad indispensable en casi cualquier campo. Si estás leyendo esto, es probable que sientas esa curiosidad o la necesidad de sumergirte en este fascinante mundo. ¡Y has llegado al lugar correcto! Mi objetivo con este artículo es desmitificar el proceso y mostrarte cómo puedes, desde hoy mismo, empezar a explorar datasets, limpiarlos, visualizarlos y extraer ideas valiosas, todo con Python. No necesitas ser un experto; solo ganas de aprender y una computadora.
Al final de esta guía, no solo habrás adquirido conocimientos prácticos, sino que también tendrás una base sólida para crear tus propios proyectos y, lo más importante, la confianza para mostrarlos. Vamos a construir juntos un camino claro, paso a paso, para que puedas decir con orgullo: “¡Sí, soy un analista de datos!”.
Metodología: Prepara Tu Entorno
Paso 0: Preparando el Entorno de Desarrollo y Dependencias
Antes de sumergirnos en los datos, necesitamos asegurarnos de que tienes todas las herramientas necesarias. Python es el corazón de nuestro trabajo, y con él, varias librerías especializadas que hacen la magia del análisis de datos.
Librerías de Python Necesarias:
- pandas: La navaja suiza para la manipulación y análisis de datos.
- numpy: Fundamental para operaciones numéricas de alto rendimiento.
- matplotlib: La base para crear gráficos estáticos, interactivos y animados.
- seaborn: Basada en matplotlib, ofrece una interfaz de alto nivel para crear gráficos estadísticos atractivos e informativos.
- scikit-learn: Imprescindible para el aprendizaje automático (machine learning), aunque en este artículo nos centraremos más en las primeras etapas del análisis.
Instalación:
La forma más sencilla de instalar estas librerías es utilizando pip, el gestor de paquetes de Python. Abre tu terminal o símbolo del sistema y ejecuta los siguientes comandos:
pip install pandas numpy matplotlib seaborn scikit-learn
Si prefieres un entorno más integrado con todas estas herramientas preconfiguradas, te recomiendo encarecidamente instalar Anaconda. Anaconda viene con Python y muchísimas librerías populares preinstaladas, además de herramientas como Jupyter Notebook, que es ideal para el análisis de datos interactivo.
Paso 1: Investigación y Selección del Dataset
Para este viaje, he elegido un dataset clásico y perfecto para principiantes: el dataset del Titanic. Es lo suficientemente complejo como para permitirnos explorar varias técnicas de análisis, pero también lo bastante sencillo como para no abrumarnos.
Dataset Seleccionado: Titanic
- Nombre: Titanic (Passenger List)
- Fuente/Método de Acceso: Este dataset es muy común y se puede encontrar en varias fuentes. Para nuestro propósito, lo descargaremos fácilmente desde el sitio de Kaggle o incluso, para versiones de ejemplo, algunas librerías como Seaborn lo tienen disponible. Optaremos por la carga directa que nos facilitan librerías como Seaborn, o si necesitamos la versión completa para un desafío, la de Kaggle es ideal.
- Breve Descripción: Contiene información sobre los pasajeros del Titanic, incluyendo si sobrevivieron o no, su edad, sexo, clase de pasajero, tarifa, puerto de embarque, etc. Es ideal para análisis de clasificación y exploración de relaciones entre variables.
Paso 2: Diseño de la Estructura del Artículo y Problemas Centrales
Para asegurarme de que este artículo sea claro y fácil de seguir, lo he estructurado en secciones lógicas, guiándote desde la preparación del entorno hasta la presentación de tus proyectos.
Índice Detallado del Artículo:
- Introducción: Tu Viaje en el Análisis de Datos Comienza Aquí
- Metodología: Prepara Tu Entorno
- Paso 0: Preparando el Entorno de Desarrollo y Dependencias
- Paso 1: Investigación y Selección del Dataset (Titanic)
- Paso 2: Diseño de la Estructura del Artículo y Problemas Centrales
- Códigos: Nuestro Primer Proyecto – Análisis del Titanic
- Paso 3: Adquisición y Carga de Datos
- Paso 4: Limpieza de Datos
- Paso 5: Análisis Exploratorio de Datos (EDA) y Visualización
- Conclusiones y Próximos Pasos
- Promoción: Construyendo un Portafolio Impresionante
- Apéndice/Recursos Adicionales
El Problema Central del Proyecto Titanic:
Para nuestro proyecto práctico con el dataset del Titanic, el problema central que abordaremos es: “¿Qué factores influyeron en la supervivencia de los pasajeros del Titanic?”
Nos haremos preguntas como:
- ¿El sexo jugó un papel crucial en la supervivencia?
- ¿La edad influyó en las tasas de supervivencia?
- ¿Hubo alguna relación entre la clase del pasajero (1ra, 2da, 3ra) y la probabilidad de sobrevivir?
- ¿La tarifa pagada o el puerto de embarque tuvieron algún impacto?
A través del EDA y la visualización, buscaremos patrones y relaciones que nos ayuden a responder estas preguntas.
Códigos: Nuestro Primer Proyecto – Análisis del Titanic
Paso 3: Adquisición y Carga de Datos
El primer paso real en cualquier proyecto de análisis de datos es obtener tus datos y cargarlos en un formato que Python pueda entender. Para el dataset del Titanic, una de las formas más sencillas de comenzar es cargarlo directamente desde la librería seaborn, que incluye este y otros datasets de ejemplo para facilitar la enseñanza y el aprendizaje.
import pandas as pd
import seaborn as sns
# Cargar el dataset del Titanic desde seaborn
df_titanic = sns.load_dataset('titanic')
# Mostrar las primeras 5 filas del DataFrame para tener una idea de los datos
print("Primeras 5 filas del dataset:")
print(df_titanic.head())
# Mostrar el tipo de datos de cada columna y la cantidad de valores no nulos
print("\nInformación del DataFrame:")
print(df_titanic.info())
Primeras 5 filas del dataset:
survived pclass sex age ... deck embark_town alive alone
0 0 3 male 22.0 ... NaN Southampton no False
1 1 1 female 38.0 ... C Cherbourg yes False
2 1 3 female 26.0 ... NaN Southampton yes True
3 1 1 female 35.0 ... C Southampton yes False
4 0 3 male 35.0 ... NaN Southampton no True
[5 rows x 15 columns]
Información del DataFrame:
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null str
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null str
8 class 891 non-null category
9 who 891 non-null str
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null str
13 alive 891 non-null str
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), str(5)
memory usage: 100.4 KB
None Explicación del Código:
import pandas as pdyimport seaborn as sns: Importamos las libreríaspandasyseaborn, que son convencionalmente abreviadas comopdysns, respectivamente.df_titanic = sns.load_dataset('titanic'): Esta línea carga el dataset ‘titanic’ directamente en un DataFrame de pandas llamadodf_titanic. Si no tuvieras conexión a internet, o quisieras una versión más específica del dataset, podrías descargarlo desde Kaggle como un archivo CSV y cargarlo conpd.read_csv('ruta/a/tu/archivo.csv').df_titanic.head(): Es una función que te permite ver las primeras cinco filas de tu DataFrame. Es una excelente práctica para obtener una vista rápida de cómo se ven tus datos y verificar si se han cargado correctamente.df_titanic.info(): Proporciona un resumen conciso del DataFrame. Incluye el número de entradas, el número de columnas, el nombre de cada columna, el número de valores no nulos en cada columna y el tipo de dato (Dtype) de cada columna. Esto es crucial para identificar valores faltantes y tipos de datos incorrectos desde el principio.
Paso 4: Limpieza de Datos
Los datos del mundo real rara vez están listos para ser analizados tal cual. La limpieza de datos es un paso crítico que implica manejar valores faltantes, duplicados, inconsistencias y corregir tipos de datos. Unos datos limpios son la base para un análisis preciso y significativo.
Manejo de Valores Nulos:
Primero, veamos dónde tenemos valores nulos y cuántos hay en cada columna.
# Contar valores nulos por columna
print("\nValores nulos por columna antes de la limpieza:")
print(df_titanic.isnull().sum())
# Estrategias para manejar valores nulos:
# 1. Eliminar filas con muchos valores nulos (ej. 'deck' tiene demasiados)
# Aunque 'deck' tiene muchos nulos, para este análisis básico, podemos simplemente ignorarla o eliminarla
# Si fuera crucial, podríamos considerar imputación más avanzada o categorización.
# Por simplicidad, y dado que no la usaremos extensivamente en este EDA básico, la dejaremos como está
# o la eliminaremos si es necesario para análisis posteriores más complejos.
# Para este ejemplo, solo nos enfocaremos en 'age' y 'embarked'
# 2. Imputar valores nulos en 'age' con la mediana
# La mediana es menos sensible a los valores atípicos que la media
df_titanic['age'].fillna(df_titanic['age'].median(), inplace=True)
# 3. Imputar valores nulos en 'embarked' con la moda (el valor más frecuente)
# 'embarked' es una variable categórica
df_titanic['embarked'].fillna(df_titanic['embarked'].mode()[0], inplace=True)
# 4. Eliminar la columna 'deck' debido a la gran cantidad de valores nulos y no ser crítica para este análisis básico
df_titanic.drop('deck', axis=1, inplace=True)
# Verificar nuevamente los valores nulos después de la limpieza
print("\nValores nulos por columna después de la limpieza (age, embarked, deck):")
print(df_titanic.isnull().sum())
Valores nulos por columna antes de la limpieza:
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int64
Valores nulos por columna después de la limpieza (age, embarked, deck):
survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
embark_town 2
alive 0
alone 0
dtype: int64Explicación del Código:
df_titanic.isnull().sum(): Calcula la cantidad de valores nulos por cada columna. Es esencial para saber dónde enfocar nuestros esfuerzos de limpieza.df_titanic['age'].fillna(df_titanic['age'].median(), inplace=True): Rellena los valores nulos en la columna ‘age’ con la mediana de las edades existentes. La mediana es una buena elección para datos numéricos cuando no quieres que los valores extremos (outliers) distorsionen tu imputación.inplace=Trueaplica los cambios directamente al DataFrame.df_titanic['embarked'].fillna(df_titanic['embarked'].mode()[0], inplace=True): Rellena los valores nulos en la columna ‘embarked’ (puerto de embarque, una variable categórica) con el valor que aparece con más frecuencia (la moda)..mode()[0]se usa porque.mode()puede devolver múltiples modas si hay un empate.df_titanic.drop('deck', axis=1, inplace=True): Elimina la columna ‘deck’ (cubierta) del DataFrame. Dado que esta columna tiene un porcentaje muy alto de valores nulos (más del 70%) y no es directamente relevante para responder nuestras preguntas centrales sobre supervivencia en este análisis inicial, su eliminación es una decisión práctica para simplificar el dataset.axis=1indica que estamos eliminando una columna, yinplace=Trueaplica el cambio.
Manejo de Duplicados:
Aunque en datasets como el del Titanic no es común encontrar filas duplicadas completas, es una buena práctica verificarlo siempre.
# Contar filas duplicadas
print("\nNúmero de filas duplicadas antes de la eliminación:", df_titanic.duplicated().sum())
# Eliminar filas duplicadas si las hay
df_titanic.drop_duplicates(inplace=True)
# Verificar después de la eliminación
print("Número de filas duplicadas después de la eliminación:", df_titanic.duplicated().sum())
Número de filas duplicadas antes de la eliminación: 111
Número de filas duplicadas después de la eliminación: 0Explicación del Código:
df_titanic.duplicated().sum(): Identifica filas completamente duplicadas y luego las suma para darte un recuento total.df_titanic.drop_duplicates(inplace=True): Elimina las filas duplicadas del DataFrame.
Corrección de Tipos de Datos (si es necesario):
A veces, pandas puede inferir un tipo de dato incorrecto (ej. un número como texto). En nuestro dataset del Titanic, las inferencias iniciales son bastante buenas, pero es crucial asegurarse de que las columnas categóricas se manejen como tal para un análisis y visualización efectivos.
# Convertir columnas categóricas a tipo 'category' para optimizar memoria y análisis
df_titanic['sex'] = df_titanic['sex'].astype('category')
df_titanic['embarked'] = df_titanic['embarked'].astype('category')
df_titanic['pclass'] = df_titanic['pclass'].astype('category')
df_titanic['survived'] = df_titanic['survived'].astype('category')
print("\nTipos de datos después de la conversión:")
print(df_titanic.info())
Tipos de datos después de la conversión:
Index: 780 entries, 0 to 890
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 780 non-null category
1 pclass 780 non-null category
2 sex 780 non-null category
3 age 676 non-null float64
4 sibsp 780 non-null int64
5 parch 780 non-null int64
6 fare 780 non-null float64
7 embarked 778 non-null category
8 class 780 non-null category
9 who 780 non-null str
10 adult_male 780 non-null bool
11 embark_town 778 non-null str
12 alive 780 non-null str
13 alone 780 non-null bool
dtypes: bool(2), category(5), float64(2), int64(2), str(3)
memory usage: 67.5 KB
None Explicación del Código:
df_titanic['columna'].astype('category'): Convierte el tipo de dato de una columna a ‘category’. Esto es beneficioso por varias razones: reduce el uso de memoria (especialmente en DataFrames grandes), y permite que algunas funciones de pandas y librerías de visualización traten estas columnas de manera más apropiada como variables categóricas. Hemos aplicado esto a ‘sex’, ‘embarked’, ‘pclass’ y ‘survived’, ya que son variables con un número limitado de valores únicos que representan categorías.
¡Con estos pasos, nuestro dataset del Titanic está mucho más limpio y listo para un análisis exploratorio profundo!
Paso 5: Análisis Exploratorio de Datos (EDA) y Visualización
Ahora que nuestros datos están limpios, es hora de sumergirnos en ellos y descubrir patrones, relaciones y anomalías. El Análisis Exploratorio de Datos (EDA) es el proceso de entender los datos usando estadísticas descriptivas y visualizaciones. Aquí, responderemos a nuestras preguntas centrales sobre la supervivencia en el Titanic.
Estadísticas Descriptivas Generales:
Comenzamos con un resumen estadístico de las columnas numéricas.
# Estadísticas descriptivas de las columnas numéricas
print("Estadísticas descriptivas de las columnas numéricas:")
print(df_titanic.describe())
# Estadísticas descriptivas de las columnas categóricas
print("\nEstadísticas descriptivas de las columnas categóricas:")
print(df_titanic.describe(include='category'))
Estadísticas descriptivas de las columnas numéricas:
age sibsp parch fare
count 676.000000 780.000000 780.000000 780.000000
mean 29.812751 0.525641 0.417949 34.829108
std 14.727098 0.988046 0.838536 52.263440
min 0.420000 0.000000 0.000000 0.000000
25% 20.000000 0.000000 0.000000 8.050000
50% 28.000000 0.000000 0.000000 15.950000
75% 39.000000 1.000000 1.000000 34.375000
max 80.000000 8.000000 6.000000 512.329200
Estadísticas descriptivas de las columnas categóricas:
survived pclass sex embarked class
count 780 780 780 778 780
unique 2 3 2 3 3
top 0 3 male S Third
freq 458 404 488 565 404Interpretación:
df.describe() nos da un resumen de conteo, media, desviación estándar, valores mínimo/máximo y cuartiles para columnas numéricas. Podemos ver la distribución de edad y tarifa, por ejemplo.df.describe(include='category') hace lo mismo para columnas categóricas, mostrando el conteo de valores únicos, el valor más frecuente (top) y su frecuencia. Esto es útil para entender la distribución de sexos, clases, etc.Análisis de Supervivencia por Sexo:
¿El sexo jugó un papel crucial en la supervivencia?
import matplotlib.pyplot as plt
# Supervivencia por Sexo
plt.figure(figsize=(6, 4))
sns.countplot(x='sex', hue='survived', data=df_titanic)
plt.title('Supervivencia por Sexo')
plt.xlabel('Sexo')
plt.ylabel('Número de Pasajeros')
plt.legend(title='Sobrevivió', labels=['No', 'Sí'])
plt.show()
# Proporción de supervivencia por sexo
print("\nProporción de Supervivencia por Sexo:")
print(df_titanic.groupby('sex')['survived'].value_counts(normalize=True).unstack())
Proporción de Supervivencia por Sexo:
survived 0 1
sex
female 0.260274 0.739726
male 0.782787 0.217213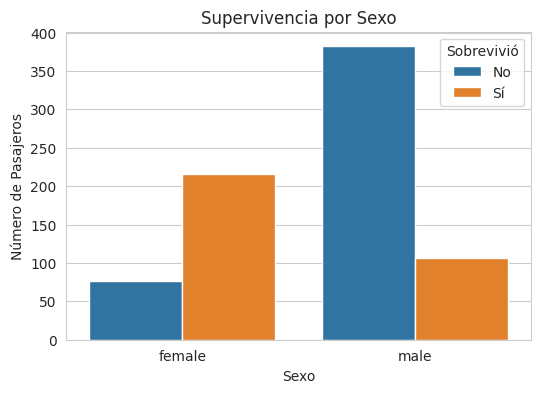
Interpretación y Observaciones:
Análisis de Supervivencia por Clase de Pasajero:
¿Hubo alguna relación entre la clase del pasajero y la probabilidad de sobrevivir?
# Supervivencia por Clase
plt.figure(figsize=(7, 5))
sns.countplot(x='pclass', hue='survived', data=df_titanic)
plt.title('Supervivencia por Clase de Pasajero')
plt.xlabel('Clase de Pasajero')
plt.ylabel('Número de Pasajeros')
plt.legend(title='Sobrevivió', labels=['No', 'Sí'])
plt.show()
# Proporción de supervivencia por clase
print("\nProporción de Supervivencia por Clase:")
print(df_titanic.groupby('pclass')['survived'].value_counts(normalize=True).unstack())
Proporción de Supervivencia por Clase:
survived 0 1
pclass
1 0.363208 0.636792
2 0.493902 0.506098
3 0.742574 0.257426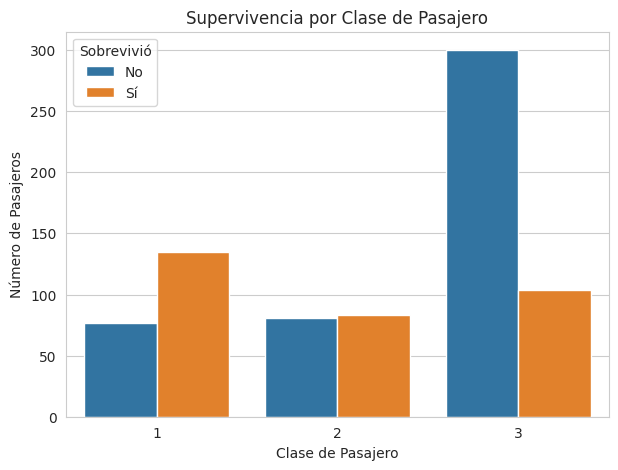
Interpretación y Observaciones:
Análisis de Supervivencia por Edad:
¿La edad influyó en las tasas de supervivencia?
# Distribución de edades por supervivencia
plt.figure(figsize=(8, 5))
sns.histplot(data=df_titanic, x='age', hue='survived', kde=True, bins=30)
plt.title('Distribución de Edad por Supervivencia')
plt.xlabel('Edad')
plt.ylabel('Frecuencia')
plt.legend(title='Sobrevivió', labels=['No', 'Sí'])
plt.show()
# Supervivencia promedio por edad (bins) - Opcional para ver tendencia
# Crear grupos de edad
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80]
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79']
df_titanic['age_band'] = pd.cut(df_titanic['age'], bins=bins, labels=labels, right=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='age_band', y='survived', data=df_titanic, ci=None)
plt.title('Tasa de Supervivencia por Grupo de Edad')
plt.xlabel('Grupo de Edad')
plt.ylabel('Tasa de Supervivencia')
plt.show()
# Eliminar la columna temporal 'age_band'
df_titanic.drop('age_band', axis=1, inplace=True)
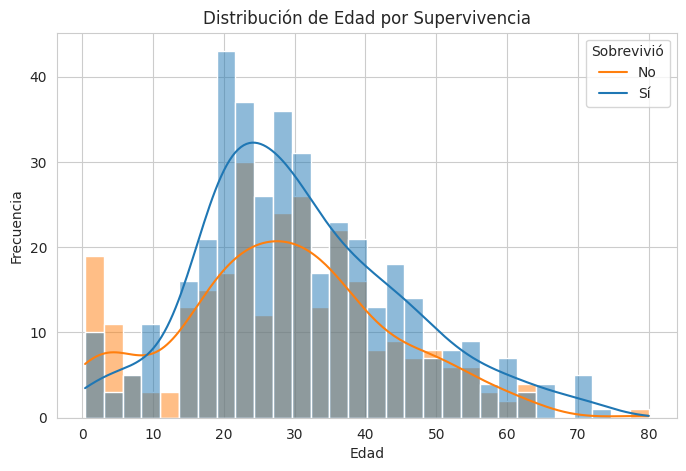
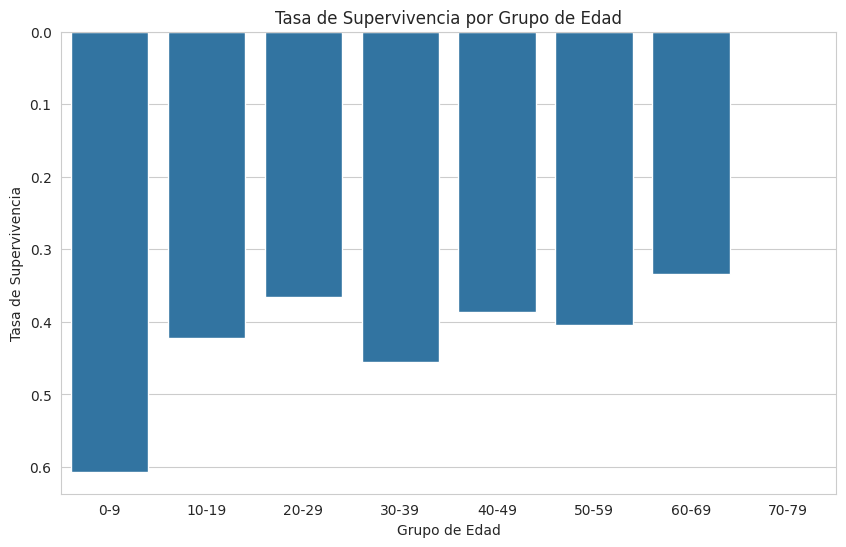
Interpretación y Observaciones:
Análisis de Supervivencia por Tarifa y Clase (Combinado):
¿La tarifa pagada o el puerto de embarque tuvieron algún impacto? Exploraremos la tarifa en combinación con la clase para una mejor perspectiva.
# Distribución de Tarifa por Supervivencia y Clase
plt.figure(figsize=(10, 6))
sns.violinplot(x='pclass', y='fare', hue='survived', data=df_titanic, palette='muted')
plt.title('Distribución de Tarifa por Clase y Supervivencia')
plt.xlabel('Clase de Pasajero')
plt.ylabel('Tarifa')
plt.legend(title='Sobrevivió', labels=['No', 'Sí'])
plt.ylim(0, 300) # Limitar el eje y para una mejor visualización de la mayoría de los datos
plt.show()
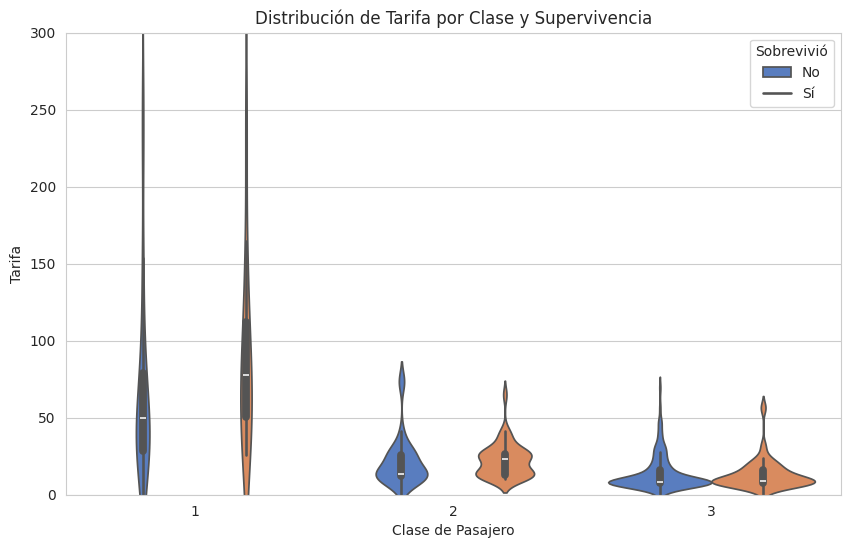
Interpretación y Observaciones:
Análisis de Supervivencia por Puerto de Embarque:
# Supervivencia por Puerto de Embarque
plt.figure(figsize=(7, 5))
sns.countplot(x='embarked', hue='survived', data=df_titanic)
plt.title('Supervivencia por Puerto de Embarque')
plt.xlabel('Puerto de Embarque')
plt.ylabel('Número de Pasajeros')
plt.legend(title='Sobrevivió', labels=['No', 'Sí'])
plt.show()
# Proporción de supervivencia por puerto de embarque
print("\nProporción de Supervivencia por Puerto de Embarque:")
print(df_titanic.groupby('embarked')['survived'].value_counts(normalize=True).unstack())
Proporción de Supervivencia por Puerto de Embarque:
survived 0 1
embarked
C 0.419355 0.580645
Q 0.655172 0.344828
S 0.628319 0.371681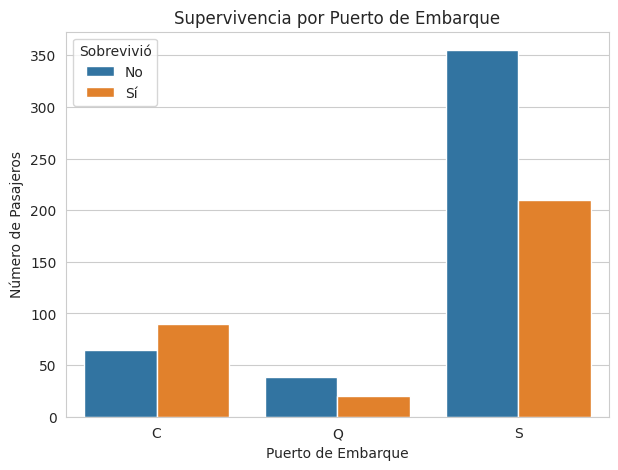
Interpretación y Observaciones:
Conclusiones y Próximos Pasos
Conclusiones Clave del Análisis del Titanic:
Próximos Pasos y Desafíos Adicionales:
Este análisis exploratorio es solo el comienzo. Aquí te presento algunas ideas para llevar este proyecto o tus futuros proyectos al siguiente nivel:
- Extrae el título de la columna ‘Name’ (ej. Mr., Mrs., Master) y analiza su impacto en la supervivencia.
- Combina ‘SibSp’ (hermanos/cónyuges a bordo) y ‘Parch’ (padres/hijos a bordo) para crear una columna ‘FamilySize’ (tamaño de la familia) y luego una ‘IsAlone’ (está solo).
- Divide tu dataset en conjuntos de entrenamiento y prueba.
- Entrena un modelo con el conjunto de entrenamiento y evalúa su rendimiento con el conjunto de prueba.
requirements.txt para listar tus dependencias (pip freeze > requirements.txt).Haber completado este análisis del Titanic es un logro fantástico, ¡pero no te lo guardes solo para ti! La clave para destacar en el mundo del análisis de datos es mostrar lo que sabes hacer. Un portafolio bien construido es tu carta de presentación.
Cómo Organizar y Presentar Tus Proyectos en GitHub:
/data: Para los datasets brutos y procesados./notebookso/src: Para tus scripts de Python o Jupyter Notebooks./reportso/visualizations: Para cualquier informe o visualización generada./README.md: El archivo más importante de tu repositorio.
requirements.txt): Incluye un archivo requirements.txt donde listas todas las librerías de Python que tu proyecto necesita. Esto permite que cualquier persona (incluidos futuros empleadores) replique tu entorno fácilmente. Puedes crearlo con pip freeze > requirements.txt.Creando un Archivo README Efectivo: Tu Historia del Proyecto
El archivo README.md es la primera impresión de tu proyecto. Debe ser claro, conciso y convincente. Piensa en él como un resumen ejecutivo de tu trabajo. Aquí te explico qué debe contener:
Un README bien elaborado no solo muestra tus habilidades técnicas, sino también tu capacidad para comunicar resultados y pensar críticamente. ¡Es una herramienta poderosa para tu carrera!
Apéndice/Recursos Adicionales
El camino del análisis de datos es un aprendizaje continuo. Aquí te dejo algunos recursos adicionales para que puedas seguir profundizando tus conocimientos:
Documentación Oficial:
Tutoriales y Cursos Recomendados:
Datasets Adicionales para Practicar:
¡No tengas miedo de experimentar y aplicar lo que has aprendido en diferentes conjuntos de datos! Cada nuevo proyecto es una oportunidad para consolidar tus habilidades.
Si te ha gustado este recorrido y quieres llevar tus habilidades al siguiente nivel con una guía aún más profunda y estructurada, te invito a explorar mi curso completo de Ciencia de Datos con Python y R. En él, cubrimos desde los fundamentos hasta técnicas avanzadas de modelado y despliegue, con proyectos prácticos que te prepararán para el mundo real.
Puedes encontrar más información y unirte a la comunidad de aprendizaje aquí:
¡Recuerda que siempre, siempre vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.