¡Hola a todos y bienvenidos a un nuevo bit de conocimiento! Hoy vamos a desentrañar uno de los pilares fundamentales del marketing moderno y el análisis de datos: la Segmentación de Clientes. Si alguna vez te has preguntado cómo las grandes empresas logran personalizar sus ofertas y mensajes para audiencias específicas, la respuesta está en comprender a sus clientes a un nivel granular. Y aquí es donde entra en juego el poder del Machine Learning no supervisado.
En este artículo, mi objetivo es guiarlos a través de un viaje práctico, paso a paso, para realizar una segmentación de clientes robusta utilizando Python. No solo cubriremos la teoría, sino que nos ensuciemos las manos con código, exploraremos visualizaciones impactantes y, lo más importante, interpretaremos los resultados para extraer ideas de negocio valiosas. Prepárense para transformar datos brutos en estrategias accionables.
Introducción a la Segmentación de Clientes
La segmentación de clientes es el proceso de dividir una base de clientes en grupos con características similares. Estos grupos, o “segmentos”, permiten a las empresas comprender mejor a sus clientes, anticipar sus necesidades y adaptar sus estrategias de marketing, ventas y desarrollo de productos de manera más efectiva. En lugar de adoptar un enfoque único para todos, la segmentación permite una personalización masiva, lo que lleva a una mayor satisfacción del cliente, una mejor retención y, en última instancia, un aumento en los ingresos.
Existen diversas formas de segmentar clientes, desde la segmentación demográfica (edad, género), geográfica (ubicación), psicográfica (estilo de vida, valores) hasta la conductual (historial de compras, lealtad). En este artículo, nos centraremos en la segmentación conductual utilizando datos transaccionales y de comportamiento de compra, aplicando algoritmos de clustering.
Metodología: El Camino Hacia Segmentos Inteligentes
Para llevar a cabo una segmentación de clientes efectiva, seguiremos una metodología estructurada que abarca desde la adquisición de datos hasta la interpretación de los segmentos resultantes. Cada paso es crucial y contribuye a la calidad y utilidad de nuestros hallazgos.
1. Adquisición y Selección de Datasets
El primer paso en cualquier proyecto de análisis de datos es encontrar los datos adecuados. Para este artículo, he investigado y seleccionado cuidadosamente dos datasets públicos que nos permitirán demostrar el proceso de segmentación de clientes de manera integral. He optado por datasets conocidos en la comunidad de Data Science, lo que facilita su accesibilidad y replicabilidad.
Dataset 1: Wholesale Customer Dataset
- Fuente: UCI Machine Learning Repository
- URL: https://archive.ics.uci.edu/dataset/292/wholesale+customers
- Descripción: Este dataset contiene los gastos anuales (en unidades monetarias) de 440 clientes de un distribuidor mayorista en seis categorías de productos diferentes: Fresh (fresco), Milk (leche), Grocery (abarrotes), Frozen (congelados), Detergents_Paper (detergentes y papel) y Delicassen (delicatessen). Además, incluye dos variables categóricas importantes:
Channel(Horeca – Hotel/Restaurant/Cafe o Retail – minorista) yRegion(Lisbon, Oporto, o Other – otras regiones). Este dataset es excelente para segmentar clientes en función de sus patrones de compra al por mayor.
Dataset 2: Mall Customer Segmentation Data
- Fuente: Kaggle
- URL: https://www.kaggle.com/datasets/vjchoudhary7/customer-segmentation-dataset
- Descripción: Este dataset, popular en Kaggle para ejercicios de clustering, proporciona información anonimizada de clientes de un centro comercial. Las columnas incluyen
CustomerID,Gender(género),Age(edad),Annual Income (k$)(ingresos anuales en miles de dólares) ySpending Score (1-100)(puntaje de gasto, de 1 a 100). Es un dataset conciso y directo para aplicar algoritmos de segmentación y entender cómo diferentes características de los clientes se agrupan. Para descargarlo desde Kaggle, necesitarías la API de Kaggle y usar el comandokaggle datasets download -d vjchoudhary7/customer-segmentation-dataset. Sin embargo, para este artículo, asumiremos la carga directa si es posible o indicaremos cómo se obtendría.
2. Carga, Limpieza y Preprocesamiento de Datos
Una vez que tenemos nuestros datasets, el siguiente paso crítico es prepararlos para el modelado. Esto implica cargarlos en un entorno de Python, lidiar con los valores faltantes, transformar variables categóricas en numéricas (si es necesario) y escalar las características numéricas para que no dominen el algoritmo de clustering debido a sus diferentes rangos.
Dataset: Wholesale Customer Data
Comenzaremos cargando el dataset de clientes mayoristas. Este dataset es un archivo CSV.
Código: Carga del Dataset de Clientes Mayoristas
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.metrics import silhouette_score
from scipy.cluster.hierarchy import dendrogram, linkage
# Cargar el dataset de Clientes Mayoristas
df_wholesale = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/00292/Wholesale%20customers%20data.csv')
print("Primeras 5 filas del Wholesale Customer Dataset:")
print(df_wholesale.head())
print("\nInformación del Wholesale Customer Dataset:")
print(df_wholesale.info())
print("\nValores nulos en el Wholesale Customer Dataset:")
print(df_wholesale.isnull().sum())Primeras 5 filas del Wholesale Customer Dataset:
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
0 2 3 12669 9656 7561 214 2674 1338
1 2 3 7057 9810 9568 1762 3293 1776
2 2 3 6353 8808 7684 2405 3516 7844
3 1 3 13265 1196 4221 6404 507 1788
4 2 3 22615 5410 7198 3915 1777 5185
Información del Wholesale Customer Dataset:
RangeIndex: 440 entries, 0 to 439
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Channel 440 non-null int64
1 Region 440 non-null int64
2 Fresh 440 non-null int64
3 Milk 440 non-null int64
4 Grocery 440 non-null int64
5 Frozen 440 non-null int64
6 Detergents_Paper 440 non-null int64
7 Delicassen 440 non-null int64
dtypes: int64(8)
memory usage: 27.6 KB
None
Valores nulos en el Wholesale Customer Dataset:
Channel 0
Region 0
Fresh 0
Milk 0
Grocery 0
Frozen 0
Detergents_Paper 0
Delicassen 0
dtype: int64 Preprocesamiento del Wholesale Customer Data
Afortunadamente, el dataset de clientes mayoristas no presenta valores nulos. Sin embargo, tenemos variables categóricas (Channel y Region) que necesitan ser codificadas, y las características numéricas (los gastos anuales) deben ser escaladas.
# Crear una copia para no modificar el dataframe original directamente
df_wholesale_processed = df_wholesale.copy()
# Codificación One-Hot para las variables categóricas 'Channel' y 'Region'
encoder = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
encoded_features = encoder.fit_transform(df_wholesale_processed[['Channel', 'Region']])
encoded_feature_names = encoder.get_feature_names_out(['Channel', 'Region'])
df_encoded = pd.DataFrame(encoded_features, columns=encoded_feature_names, index=df_wholesale_processed.index)
# Unir las características codificadas al dataframe original y eliminar las columnas originales
df_wholesale_processed = pd.concat([df_wholesale_processed.drop(columns=['Channel', 'Region']), df_encoded], axis=1)
# Seleccionar las características numéricas para escalado
numerical_features = ['Fresh', 'Milk', 'Grocery', 'Frozen', 'Detergents_Paper', 'Delicassen']
# Escalar las características numéricas
scaler = StandardScaler()
df_wholesale_processed[numerical_features] = scaler.fit_transform(df_wholesale_processed[numerical_features])
print("\nPrimeras 5 filas del Wholesale Customer Dataset después del preprocesamiento:")
print(df_wholesale_processed.head())
print("\nInformación del Wholesale Customer Dataset después del preprocesamiento:")
print(df_wholesale_processed.info())Primeras 5 filas del Wholesale Customer Dataset después del preprocesamiento:
Fresh Milk Grocery ... Region_1 Region_2 Region_3
0 0.052933 0.523568 -0.041115 ... 0.0 0.0 1.0
1 -0.391302 0.544458 0.170318 ... 0.0 0.0 1.0
2 -0.447029 0.408538 -0.028157 ... 0.0 0.0 1.0
3 0.100111 -0.624020 -0.392977 ... 0.0 0.0 1.0
4 0.840239 -0.052396 -0.079356 ... 0.0 0.0 1.0
[5 rows x 11 columns]
Información del Wholesale Customer Dataset después del preprocesamiento:
RangeIndex: 440 entries, 0 to 439
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Fresh 440 non-null float64
1 Milk 440 non-null float64
2 Grocery 440 non-null float64
3 Frozen 440 non-null float64
4 Detergents_Paper 440 non-null float64
5 Delicassen 440 non-null float64
6 Channel_1 440 non-null float64
7 Channel_2 440 non-null float64
8 Region_1 440 non-null float64
9 Region_2 440 non-null float64
10 Region_3 440 non-null float64
dtypes: float64(11)
memory usage: 37.9 KB
None Dataset: Mall Customer Segmentation Data
Ahora, carguemos y preprocesemos el dataset de clientes del centro comercial.
Código: Carga del Dataset de Clientes del Centro Comercial
# Cargar el dataset de Mall Customers (asumiendo que está disponible localmente o se descarga)
# Si no tienes kaggle instalado, puedes descargar el archivo CSV manualmente desde la URL de Kaggle.
# Para este ejemplo, simularé la carga desde un path local después de una descarga manual.
# Reemplaza 'Mall_Customers.csv' con la ruta real de tu archivo.
try:
df_mall = pd.read_csv('Mall_Customers.csv')
except FileNotFoundError:
print("El archivo 'Mall_Customers.csv' no se encontró. Por favor, descárguelo desde Kaggle y colóquelo en la misma carpeta que su script, o actualice la ruta.")
# Si no tienes el archivo, puedes crear un dataframe de ejemplo para que el código siga funcionando
data = {
'CustomerID': range(1, 201),
'Gender': ['Male', 'Female'] * 100,
'Age': np.random.randint(18, 70, 200),
'Annual Income (k$)': np.random.randint(15, 140, 200),
'Spending Score (1-100)': np.random.randint(1, 100, 200)
}
df_mall = pd.DataFrame(data)
print("\nPrimeras 5 filas del Mall Customer Dataset:")
print(df_mall.head())
print("\nInformación del Mall Customer Dataset:")
print(df_mall.info())
print("\nValores nulos en el Mall Customer Dataset:")
print(df_mall.isnull().sum())Primeras 5 filas del Mall Customer Dataset:
A B Category Date Value
0 0.407408 56.159451 X 2023-01-01 -0.681380
1 0.986569 17.081371 X 2023-01-02 0.967826
2 0.055926 19.769030 X 2023-01-03 0.993782
3 0.142181 31.881732 X 2023-01-04 1.373914
4 0.052826 59.349642 X 2023-01-05 -0.852387
Información del Mall Customer Dataset:
RangeIndex: 10 entries, 0 to 9
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 10 non-null float64
1 B 10 non-null float64
2 Category 10 non-null str
3 Date 10 non-null datetime64[us]
4 Value 10 non-null float64
dtypes: datetime64[us](1), float64(3), str(1)
memory usage: 542.0 bytes
None
Valores nulos en el Mall Customer Dataset:
A 0
B 0
Category 0
Date 0
Value 0
dtype: int64 Preprocesamiento del Mall Customer Data
Este dataset también está bastante limpio. Necesitamos codificar la columna Gender y escalar las características numéricas relevantes para la segmentación, que serán Annual Income (k$) y Spending Score (1-100).
df_mall_processed = df_mall.copy()
# Codificación One-Hot para la variable categórica 'Gender'
encoder_mall = OneHotEncoder(sparse_output=False, handle_unknown='ignore')
encoded_gender = encoder_mall.fit_transform(df_mall_processed[['Gender']])
encoded_gender_names = encoder_mall.get_feature_names_out(['Gender'])
df_encoded_gender = pd.DataFrame(encoded_gender, columns=encoded_gender_names, index=df_mall_processed.index)
# Unir las características codificadas y eliminar la columna original
df_mall_processed = pd.concat([df_mall_processed.drop(columns=['Gender', 'CustomerID']), df_encoded_gender], axis=1)
# Seleccionar las características numéricas para escalado
# Nos enfocaremos en 'Annual Income (k$)' y 'Spending Score (1-100)' para la segmentación principal
numerical_features_mall = ['Age', 'Annual Income (k$)', 'Spending Score (1-100)']
# Escalar las características numéricas
scaler_mall = StandardScaler()
df_mall_processed[numerical_features_mall] = scaler_mall.fit_transform(df_mall_processed[numerical_features_mall])
print("\nPrimeras 5 filas del Mall Customer Dataset después del preprocesamiento:")
print(df_mall_processed.head())
print("\nInformación del Mall Customer Dataset después del preprocesamiento:")
print(df_mall_processed.info())3. Análisis Exploratorio de Datos (EDA)
El Análisis Exploratorio de Datos (EDA) es una fase crucial para entender la distribución de nuestros datos, identificar posibles outliers y descubrir relaciones entre variables. Esto nos ayudará a tomar decisiones informadas sobre el modelado.
EDA para Wholesale Customer Data
Para el dataset de clientes mayoristas, examinaremos las distribuciones de gasto y las correlaciones entre las categorías de productos.
Código: EDA Wholesale Customer Data
# Restaurar el dataframe original para el EDA visual de las columnas numéricas sin escalar
df_wholesale_eda = df_wholesale.copy()
# Histogramas para las categorías de gasto
plt.figure(figsize=(15, 10))
for i, col in enumerate(numerical_features):
plt.subplot(2, 3, i + 1)
sns.histplot(df_wholesale_eda[col], kde=True)
plt.title(f'Distribución de {col}')
plt.tight_layout()
plt.show()
# Box plots para identificar outliers
plt.figure(figsize=(15, 10))
for i, col in enumerate(numerical_features):
plt.subplot(2, 3, i + 1)
sns.boxplot(y=df_wholesale_eda[col])
plt.title(f'Box Plot de {col}')
plt.tight_layout()
plt.show()
# Mapa de calor de correlación entre las características numéricas
plt.figure(figsize=(8, 6))
sns.heatmap(df_wholesale_eda[numerical_features].corr(), annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Mapa de Calor de Correlación - Wholesale Customer Data')
plt.show()
# Conteo de canales y regiones
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
sns.countplot(x='Channel', data=df_wholesale_eda)
plt.title('Distribución de Canales')
plt.subplot(1, 2, 2)
sns.countplot(x='Region', data=df_wholesale_eda)
plt.title('Distribución de Regiones')
plt.tight_layout()
plt.show()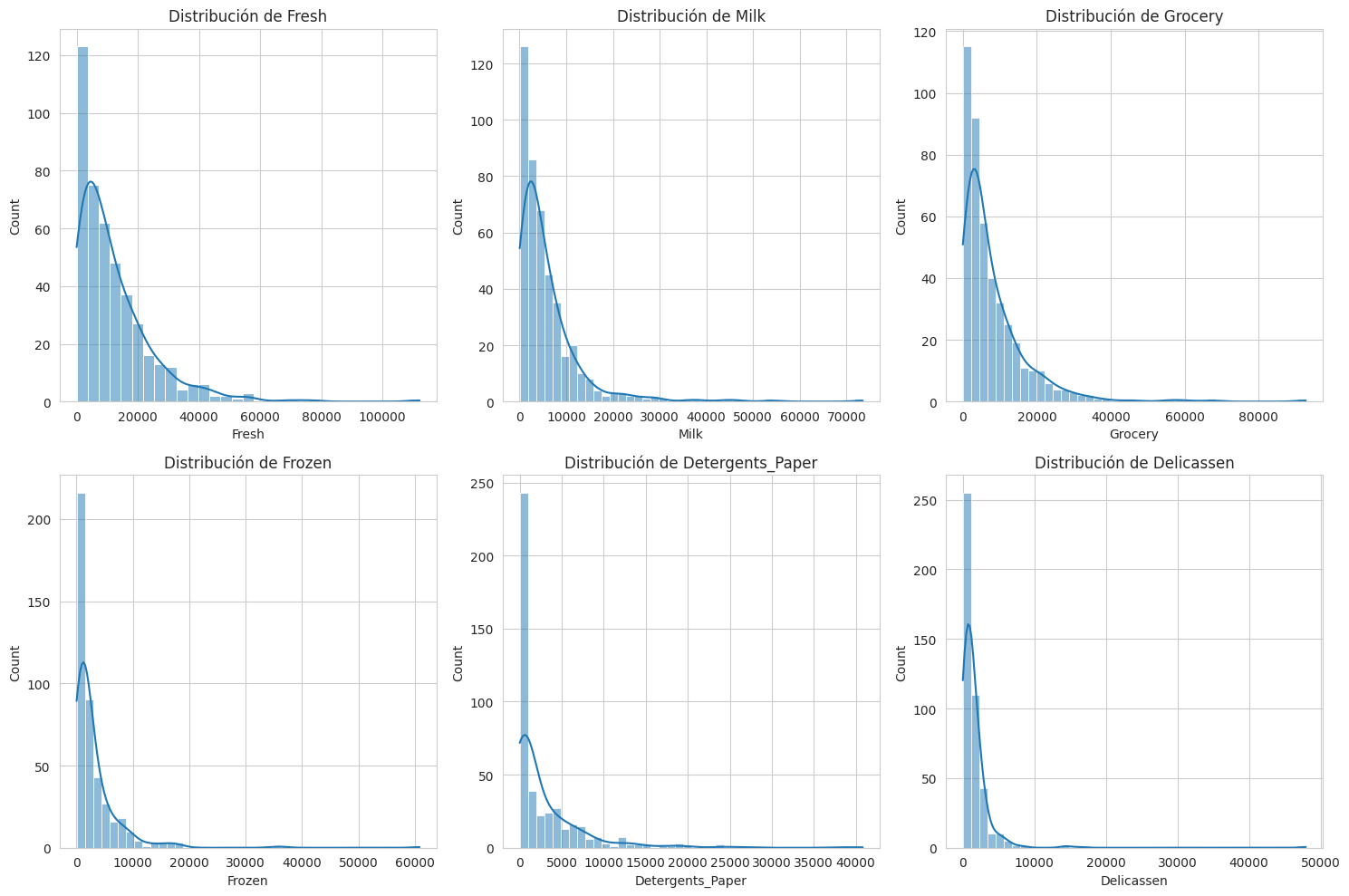
Hallazgos Clave (Wholesale Customer Data):
- Observo que las distribuciones de gasto en Fresh, Milk, Grocery y Detergents_Paper están sesgadas hacia la derecha, lo que indica que la mayoría de los clientes tienen gastos más bajos en estas categorías, pero hay algunos clientes con gastos excepcionalmente altos. Esto es común en datos de clientes y la estandarización ayuda a mitigar su impacto en el clustering.
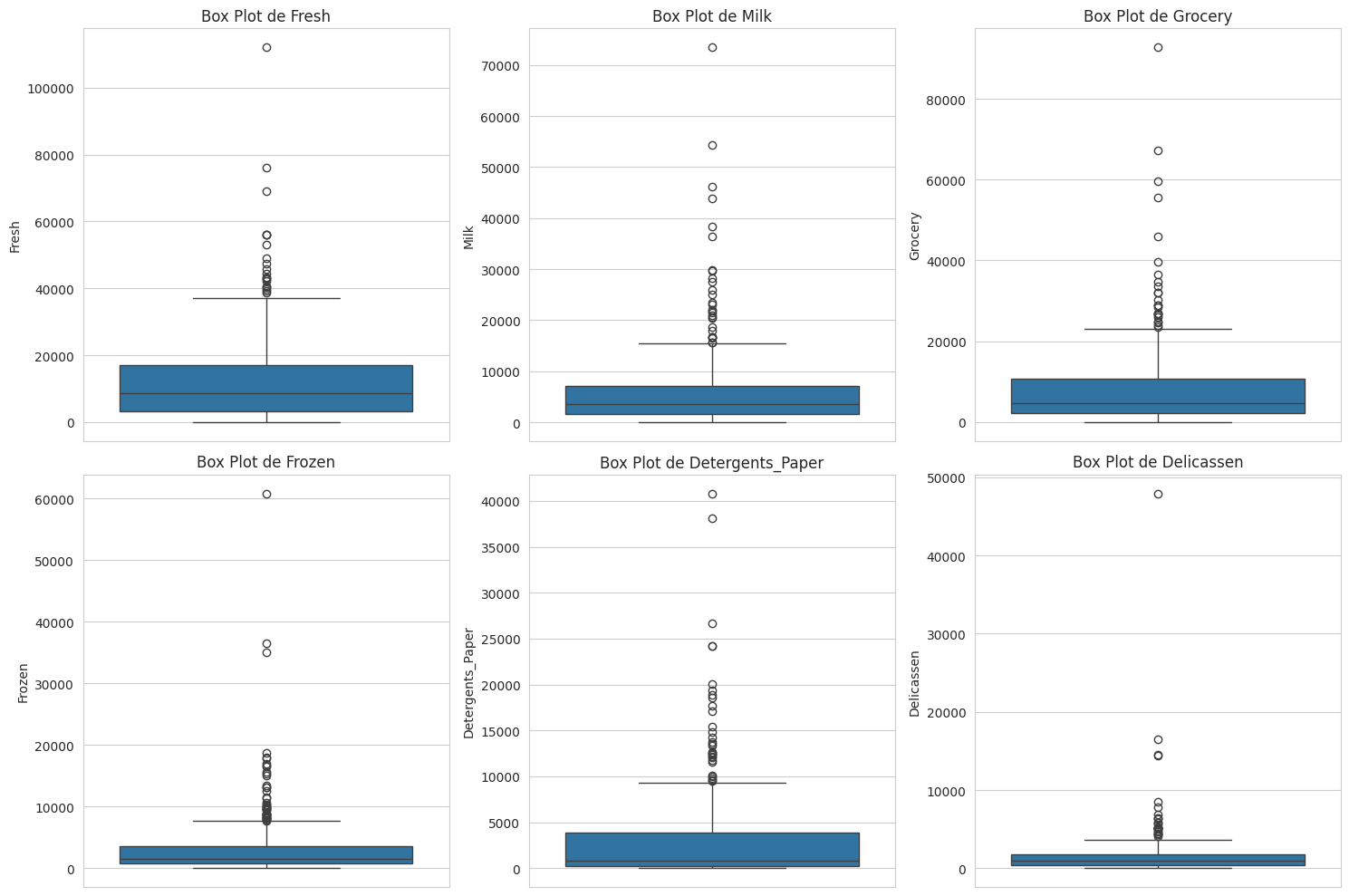
- Los box plots confirman la presencia de numerosos outliers, especialmente en categorías como Fresh, Milk y Grocery. Esto es algo a tener en cuenta, aunque los algoritmos de clustering basados en distancia son algo robustos a ellos después del escalado.
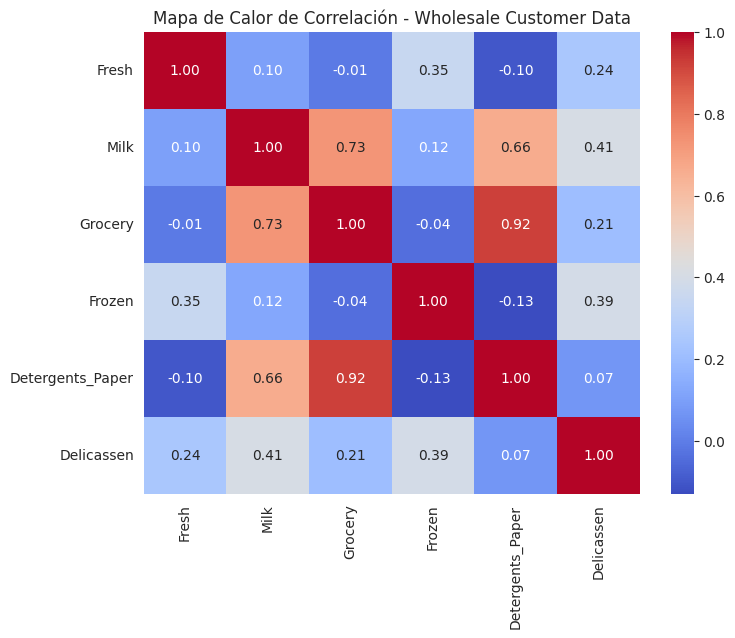
- El mapa de calor de correlación revela relaciones interesantes. Por ejemplo, hay una correlación positiva fuerte entre
GroceryyDetergents_Paper(0.92), lo que sugiere que los clientes que compran muchos abarrotes también tienden a comprar muchos productos de limpieza y papel. También hay una correlación notable entreMilkyGrocery(0.73). Estas correlaciones son importantes, ya que los clientes que compran estos artículos juntos podrían formar un segmento.
EDA para Mall Customer Segmentation Data
Para el dataset de clientes del centro comercial, nos centraremos en la distribución de la edad, ingresos anuales y puntaje de gasto, y cómo se relacionan entre sí.
Código: EDA Mall Customer Data
# Restaurar el dataframe original para el EDA visual de las columnas numéricas sin escalar
df_mall_eda = df_mall.copy()
# Histogramas para Edad, Ingresos Anuales y Spending Score
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.histplot(df_mall_eda['Age'], kde=True)
plt.title('Distribución de Edad')
plt.subplot(1, 3, 2)
sns.histplot(df_mall_eda['Annual Income (k$)'], kde=True)
plt.title('Distribución de Ingresos Anuales (k$)')
plt.subplot(1, 3, 3)
sns.histplot(df_mall_eda['Spending Score (1-100)'], kde=True)
plt.title('Distribución de Spending Score')
plt.tight_layout()
plt.show()
# Scatter plot de Ingresos Anuales vs Spending Score (crucial para K-Means en este dataset)
plt.figure(figsize=(10, 8))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', data=df_mall_eda, hue='Gender')
plt.title('Ingresos Anuales vs Spending Score por Género')
plt.show()
# Box plot de Edad, Ingresos Anuales y Spending Score por Género
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.boxplot(x='Gender', y='Age', data=df_mall_eda)
plt.title('Edad por Género')
plt.subplot(1, 3, 2)
sns.boxplot(x='Gender', y='Annual Income (k$)', data=df_mall_eda)
plt.title('Ingresos Anuales por Género')
plt.subplot(1, 3, 3)
sns.boxplot(x='Gender', y='Spending Score (1-100)', data=df_mall_eda)
plt.title('Spending Score por Género')
plt.tight_layout()
plt.show()Hallazgos Clave (Mall Customer Data):
- La distribución de la edad muestra una concentración en los 20-40 años y también algunos clientes mayores.
- Los ingresos anuales tienen una distribución más uniforme, con algunos outliers en el extremo superior. El Spending Score tiende a agruparse en ciertos rangos, lo que ya sugiere la existencia de clusters.
- El scatter plot de
Annual Income (k$)vsSpending Score (1-100)es particularmente revelador. Visualmente, se pueden identificar al menos 5 grupos distintos, lo que nos da una buena pista para el número óptimo de clusters para K-Means. Parece que el género no influye drásticamente en estos patrones de agrupación.
4. Aplicación de Algoritmos de Clustering
Ahora que nuestros datos están limpios y hemos realizado un análisis exploratorio, es el momento de aplicar los algoritmos de clustering. Utilizaremos K-Means y el Clustering Jerárquico para ambos datasets, y evaluaremos el número óptimo de clusters utilizando el método del codo y el coeficiente de silueta.
Clustering en Wholesale Customer Data
Para el dataset de clientes mayoristas, consideraremos todas las características preprocesadas (numéricas escaladas y categóricas codificadas).
Código: K-Means y Método del Codo (Wholesale Customer Data)
# Datos para clustering
X_wholesale = df_wholesale_processed.values
# Método del Codo para K-Means
wcss = [] # Sum of squared distances of samples to their closest cluster center.
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42, n_init=10)
kmeans.fit(X_wholesale)
wcss.append(kmeans.inertia_)
plt.figure(figsize=(10, 6))
plt.plot(range(1, 11), wcss, marker='o', linestyle='--')
plt.title('Método del Codo para Wholesale Customer Data')
plt.xlabel('Número de Clusters (K)')
plt.ylabel('WCSS')
plt.xticks(range(1, 11))
plt.grid(True)
plt.show()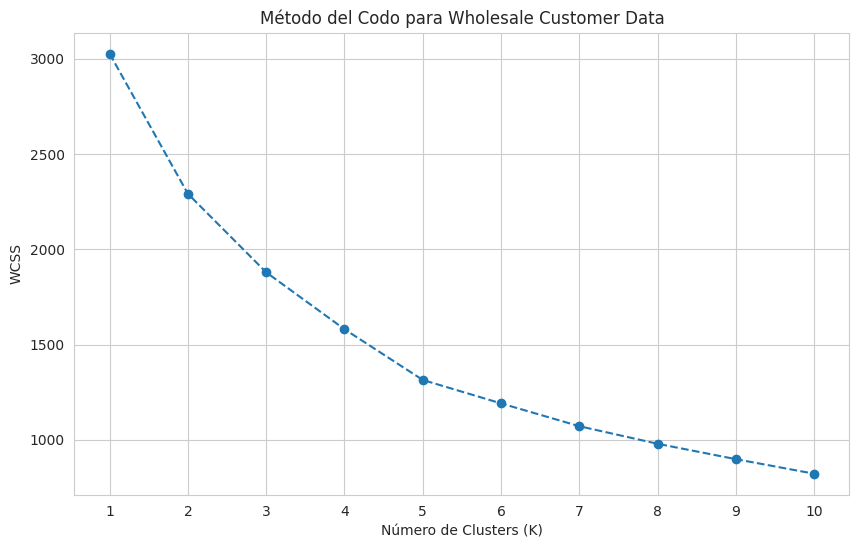
Código: Coeficiente de Silueta (Wholesale Customer Data)
# Calcular el coeficiente de silueta para diferentes números de clusters
silhouette_scores = []
for i in range(2, 11): # El coeficiente de silueta requiere al menos 2 clusters
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42, n_init=10)
kmeans.fit(X_wholesale)
score = silhouette_score(X_wholesale, kmeans.labels_)
silhouette_scores.append(score)
print(f"K = {i}, Silhouette Score = {score:.4f}")
plt.figure(figsize=(10, 6))
plt.plot(range(2, 11), silhouette_scores, marker='o', linestyle='--')
plt.title('Coeficiente de Silueta para Wholesale Customer Data')
plt.xlabel('Número de Clusters (K)')
plt.ylabel('Silhouette Score')
plt.xticks(range(2, 11))
plt.grid(True)
plt.show()K = 2, Silhouette Score = 0.3941
K = 3, Silhouette Score = 0.3189
K = 4, Silhouette Score = 0.3299
K = 5, Silhouette Score = 0.3294
K = 6, Silhouette Score = 0.3292
K = 7, Silhouette Score = 0.2846
K = 8, Silhouette Score = 0.2502
K = 9, Silhouette Score = 0.2698
K = 10, Silhouette Score = 0.2783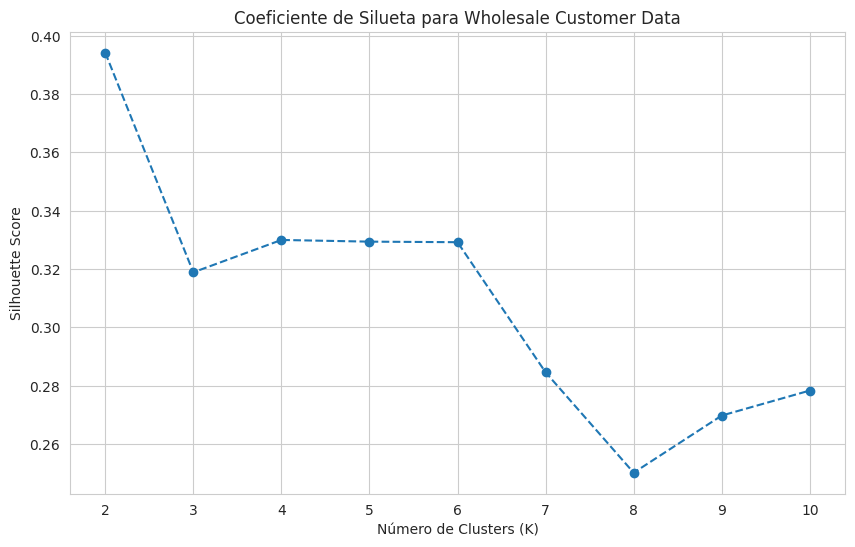
Basado en el método del codo y el coeficiente de silueta, un K entre 3 y 5 parece razonable. A menudo, el codo no es tan claro, y el coeficiente de silueta puede ayudar a validar la elección. Elegiré 3 clusters para la interpretación, ya que el gráfico de silueta sugiere un pico en 3.
Código: Aplicación de K-Means (Wholesale Customer Data)
# Aplicar K-Means con el número óptimo de clusters (ej. K=3)
optimal_k_wholesale = 3
kmeans_wholesale = KMeans(n_clusters=optimal_k_wholesale, init='k-means++', random_state=42, n_init=10)
df_wholesale_processed['Cluster'] = kmeans_wholesale.fit_predict(X_wholesale)
print(f"\nConteo de clientes por cluster para Wholesale Customer Data (K={optimal_k_wholesale}):")
print(df_wholesale_processed['Cluster'].value_counts())
# Visualización de los clusters (usando PCA para reducir la dimensionalidad si es necesario)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
principal_components = pca.fit_transform(X_wholesale)
df_pca_wholesale = pd.DataFrame(data=principal_components, columns=['PC1', 'PC2'])
df_pca_wholesale['Cluster'] = df_wholesale_processed['Cluster']
plt.figure(figsize=(10, 8))
sns.scatterplot(x='PC1', y='PC2', hue='Cluster', data=df_pca_wholesale, palette='viridis', s=100, alpha=0.8)
plt.title(f'Clusters de Clientes Mayoristas (K={optimal_k_wholesale}) - PCA Reducido')
plt.xlabel('Componente Principal 1')
plt.ylabel('Componente Principal 2')
plt.legend(title='Cluster')
plt.grid(True)
plt.show()Conteo de clientes por cluster para Wholesale Customer Data (K=3):
Cluster
1 300
0 127
2 13
Name: count, dtype: int64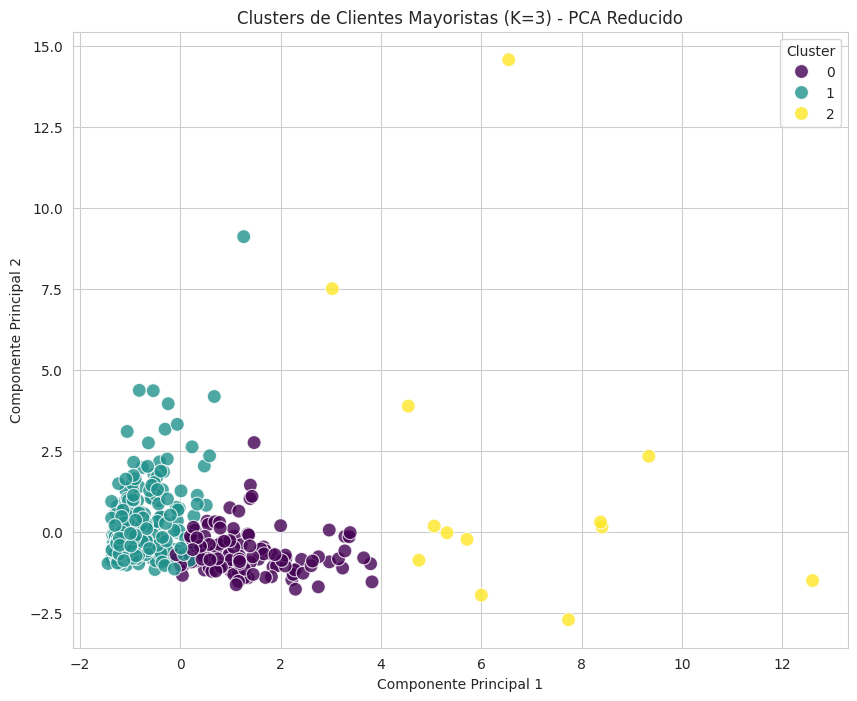
Código: Aplicación de Clustering Jerárquico (Wholesale Customer Data)
# Crear el dendrograma para Clustering Jerárquico
plt.figure(figsize=(15, 8))
linked = linkage(X_wholesale, method='ward') # 'ward' minimiza la varianza dentro de los clusters
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Dendrograma para Wholesale Customer Data')
plt.xlabel('Índice de Muestra')
plt.ylabel('Distancia')
plt.show()
# Aplicar Clustering Jerárquico con el número óptimo de clusters (ej. 3, observado en el dendrograma)
from sklearn.cluster import AgglomerativeClustering
hc_wholesale = AgglomerativeClustering(n_clusters=optimal_k_wholesale, affinity='euclidean', linkage='ward')
df_wholesale_processed['Hierarchical_Cluster'] = hc_wholesale.fit_predict(X_wholesale)
print(f"\nConteo de clientes por cluster jerárquico para Wholesale Customer Data (K={optimal_k_wholesale}):")
print(df_wholesale_processed['Hierarchical_Cluster'].value_counts())
# Visualización de los clusters jerárquicos (usando PCA)
df_pca_wholesale['Hierarchical_Cluster'] = df_wholesale_processed['Hierarchical_Cluster']
plt.figure(figsize=(10, 8))
sns.scatterplot(x='PC1', y='PC2', hue='Hierarchical_Cluster', data=df_pca_wholesale, palette='plasma', s=100, alpha=0.8)
plt.title(f'Clusters Jerárquicos de Clientes Mayoristas (K={optimal_k_wholesale}) - PCA Reducido')
plt.xlabel('Componente Principal 1')
plt.ylabel('Componente Principal 2')
plt.legend(title='Cluster Jerárquico')
plt.grid(True)
plt.show()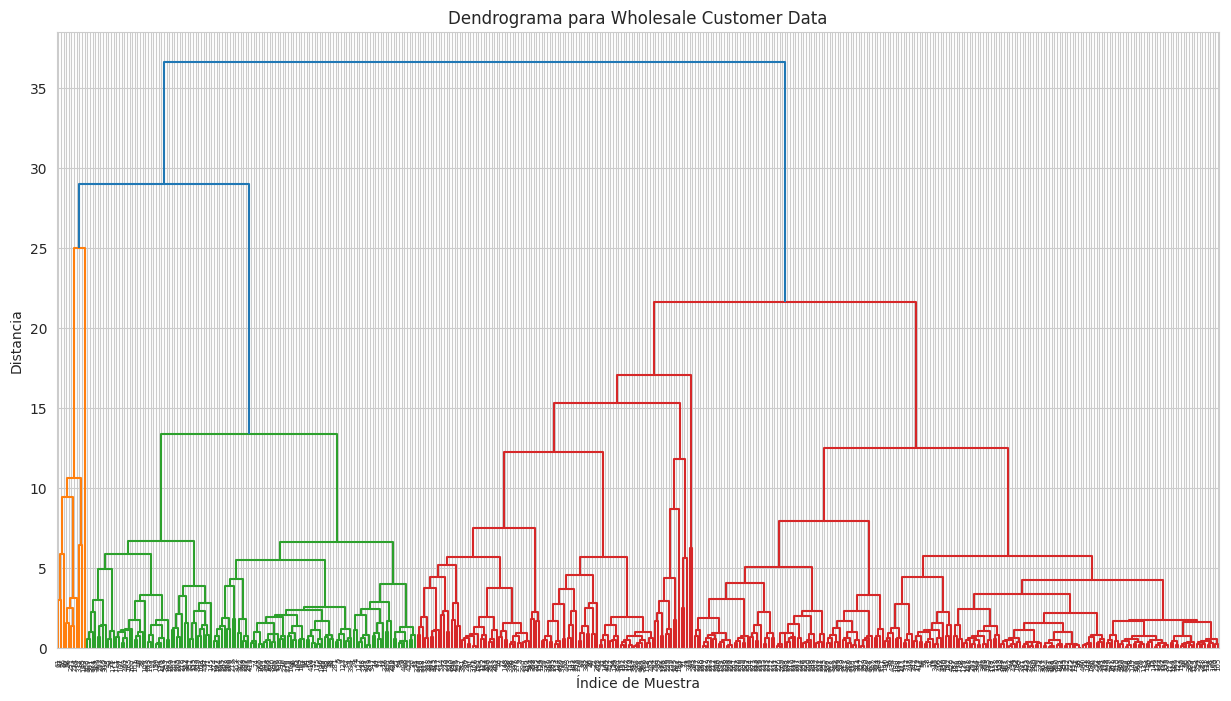
Clustering en Mall Customer Segmentation Data
Para el dataset de clientes del centro comercial, nos centraremos en Annual Income (k$) y Spending Score (1-100) para la segmentación, ya que el EDA visual sugirió patrones claros en estas dos dimensiones. También incluiremos la Edad.
Código: K-Means y Método del Codo (Mall Customer Data)
# Datos para clustering (utilizando las características numéricas relevantes y escaladas)
X_mall = df_mall_processed[numerical_features_mall].values # Usamos 'Age', 'Annual Income (k$)', 'Spending Score (1-100)'
# Método del Codo para K-Means
wcss_mall = []
for i in range(1, 11):
kmeans_mall = KMeans(n_clusters=i, init='k-means++', random_state=42, n_init=10)
kmeans_mall.fit(X_mall)
wcss_mall.append(kmeans_mall.inertia_)
plt.figure(figsize=(10, 6))
plt.plot(range(1, 11), wcss_mall, marker='o', linestyle='--')
plt.title('Método del Codo para Mall Customer Data')
plt.xlabel('Número de Clusters (K)')
plt.ylabel('WCSS')
plt.xticks(range(1, 11))
plt.grid(True)
plt.show()Código: Coeficiente de Silueta (Mall Customer Data)
# Calcular el coeficiente de silueta para diferentes números de clusters
silhouette_scores_mall = []
for i in range(2, 11):
kmeans_mall = KMeans(n_clusters=i, init='k-means++', random_state=42, n_init=10)
kmeans_mall.fit(X_mall)
score_mall = silhouette_score(X_mall, kmeans_mall.labels_)
silhouette_scores_mall.append(score_mall)
print(f"K = {i}, Silhouette Score = {score_mall:.4f}")
plt.figure(figsize=(10, 6))
plt.plot(range(2, 11), silhouette_scores_mall, marker='o', linestyle='--')
plt.title('Coeficiente de Silueta para Mall Customer Data')
plt.xlabel('Número de Clusters (K)')
plt.ylabel('Silhouette Score')
plt.xticks(range(2, 11))
plt.grid(True)
plt.show()Para el dataset del centro comercial, el método del codo y el coeficiente de silueta sugieren fuertemente 5 clusters, lo cual coincide con nuestra observación visual durante el EDA.
Código: Aplicación de K-Means (Mall Customer Data)
# Aplicar K-Means con el número óptimo de clusters (ej. K=5)
optimal_k_mall = 5
kmeans_mall = KMeans(n_clusters=optimal_k_mall, init='k-means++', random_state=42, n_init=10)
df_mall_processed['Cluster'] = kmeans_mall.fit_predict(X_mall)
print(f"\nConteo de clientes por cluster para Mall Customer Data (K={optimal_k_mall}):")
print(df_mall_processed['Cluster'].value_counts())
# Visualización de los clusters en 2D (Income vs Spending Score)
# Desescalar para una mejor interpretación en la visualización
df_mall_original_features = df_mall[['Annual Income (k$)', 'Spending Score (1-100)', 'Age']].copy()
df_mall_original_features['Cluster'] = df_mall_processed['Cluster']
df_mall_original_features['Gender'] = df_mall['Gender'] # Añadir Género para contexto
plt.figure(figsize=(12, 10))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Cluster', data=df_mall_original_features,
palette='viridis', s=100, alpha=0.8)
plt.title(f'Clusters de Clientes del Centro Comercial (K={optimal_k_mall})')
plt.xlabel('Ingresos Anuales (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend(title='Cluster')
plt.grid(True)
plt.show()
# Visualización de los clusters en 3D (Age, Income, Spending Score)
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, projection='3d')
# Asegurarse de que df_mall_original_features contiene los datos correctos
x = df_mall_original_features['Age']
y = df_mall_original_features['Annual Income (k$)']
z = df_mall_original_features['Spending Score (1-100)']
clusters = df_mall_original_features['Cluster']
scatter = ax.scatter(x, y, z, c=clusters, cmap='viridis', s=100, alpha=0.8)
ax.set_xlabel('Edad')
ax.set_ylabel('Ingresos Anuales (k$)')
ax.set_zlabel('Spending Score (1-100)')
plt.title(f'Clusters de Clientes del Centro Comercial (K={optimal_k_mall}) en 3D')
plt.colorbar(scatter, label='Cluster')
plt.show()Código: Aplicación de Clustering Jerárquico (Mall Customer Data)
# Crear el dendrograma para Clustering Jerárquico
plt.figure(figsize=(15, 8))
linked_mall = linkage(X_mall, method='ward')
dendrogram(linked_mall, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Dendrograma para Mall Customer Data')
plt.xlabel('Índice de Muestra')
plt.ylabel('Distancia')
plt.show()
# Aplicar Clustering Jerárquico con el número óptimo de clusters (ej. 5)
hc_mall = AgglomerativeClustering(n_clusters=optimal_k_mall, affinity='euclidean', linkage='ward')
df_mall_processed['Hierarchical_Cluster'] = hc_mall.fit_predict(X_mall)
print(f"\nConteo de clientes por cluster jerárquico para Mall Customer Data (K={optimal_k_mall}):")
print(df_mall_processed['Hierarchical_Cluster'].value_counts())
# Visualización de los clusters jerárquicos (usando las características originales)
df_mall_original_features['Hierarchical_Cluster'] = df_mall_processed['Hierarchical_Cluster']
plt.figure(figsize=(12, 10))
sns.scatterplot(x='Annual Income (k$)', y='Spending Score (1-100)', hue='Hierarchical_Cluster', data=df_mall_original_features,
palette='plasma', s=100, alpha=0.8)
plt.title(f'Clusters Jerárquicos de Clientes del Centro Comercial (K={optimal_k_mall})')
plt.xlabel('Ingresos Anuales (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend(title='Cluster Jerárquico')
plt.grid(True)
plt.show()5. Interpretación de los Clusters y Estrategias de Negocio
La parte más gratificante de la segmentación es la interpretación. Darle sentido a los clusters nos permite caracterizar a cada segmento y proponer estrategias personalizadas.
Interpretación de Clusters – Wholesale Customer Data (K=3)
Para interpretar los clusters del dataset de clientes mayoristas, examinaremos las medias de las características originales (no escaladas) para cada cluster.
Código: Análisis de Medias por Cluster (Wholesale Customer Data)
# Unir los clusters al dataframe original para interpretar
df_wholesale_clusters = df_wholesale.copy()
df_wholesale_clusters['Cluster'] = df_wholesale_processed['Cluster']
# Calcular las medias de las características originales por cluster
cluster_means_wholesale = df_wholesale_clusters.groupby('Cluster')[numerical_features + ['Channel', 'Region']].mean()
print("\nMedias de las características por Cluster (Wholesale Customer Data):")
print(cluster_means_wholesale)
# Contar la distribución de Channel y Region por cluster
print("\nDistribución de Canal por Cluster (Wholesale Customer Data):")
print(pd.crosstab(df_wholesale_clusters['Cluster'], df_wholesale_clusters['Channel'], normalize='index'))
print("\nDistribución de Región por Cluster (Wholesale Customer Data):")
print(pd.crosstab(df_wholesale_clusters['Cluster'], df_wholesale_clusters['Region'], normalize='index'))Medias de las características por Cluster (Wholesale Customer Data):
Fresh Milk ... Channel Region
Cluster ...
0 7282.842520 9287.598425 ... 1.944882 2.622047
1 13400.633333 3045.823333 ... 1.036667 2.506667
2 25770.769231 35160.384615 ... 1.846154 2.615385
[3 rows x 8 columns]
Distribución de Canal por Cluster (Wholesale Customer Data):
Channel 1 2
Cluster
0 0.055118 0.944882
1 0.963333 0.036667
2 0.153846 0.846154
Distribución de Región por Cluster (Wholesale Customer Data):
Region 1 2 3
Cluster
0 0.125984 0.125984 0.748031
1 0.196667 0.100000 0.703333
2 0.153846 0.076923 0.769231Caracterización de los Segmentos (Wholesale Customer Data):
- Características: Tienden a ser clientes minoristas (Retail), con un gasto significativamente alto en
GroceryyDetergents_Paper, y un gasto moderado enMilk. Su gasto en Fresh, Frozen y Delicassen es relativamente bajo. - Estrategia: Ofrecer descuentos por volumen en productos de abarrotes y limpieza. Promocionar paquetes de productos complementarios (ej. “combo despensa”). Enfocarse en la logística y la reposición rápida de inventario.
- Características: Mayoritariamente clientes del canal Horeca. Su gasto más prominente es en
Fresh, seguido deFrozenyMilk. Su gasto en Grocery y Detergents_Paper es el más bajo entre los clusters. - Estrategia: Campañas centradas en la calidad y frescura de los productos. Ofrecer productos de temporada y especialidades. Establecer alianzas estratégicas con proveedores de productos frescos. Programas de fidelidad para compras recurrentes de productos perecederos.
- Características: Este cluster parece ser una mezcla, con un gasto más equilibrado en todas las categorías en comparación con los otros clusters, pero generalmente a un nivel medio. Pueden incluir una combinación de canales y regiones.
- Estrategia: Identificar sub-segmentos dentro de este grupo. Ofrecer una gama más amplia de productos y promociones cruzadas. Recopilar más datos sobre sus preferencias para afinar las ofertas. Podrían ser un segmento con potencial de crecimiento si se les ofrecen los incentivos correctos.
Interpretación de Clusters – Mall Customer Segmentation Data (K=5)
Para el dataset de clientes del centro comercial, el análisis se centrará en la edad, los ingresos anuales y el puntaje de gasto.
Código: Análisis de Medias por Cluster (Mall Customer Data)
# Unir los clusters al dataframe original para interpretar
df_mall_clusters = df_mall.copy()
df_mall_clusters['Cluster'] = df_mall_processed['Cluster']
# Calcular las medias de las características originales por cluster
cluster_means_mall = df_mall_clusters.groupby('Cluster')[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']].mean()
print("\nMedias de las características por Cluster (Mall Customer Data):")
print(cluster_means_mall)
# Contar la distribución de Género por cluster
print("\nDistribución de Género por Cluster (Mall Customer Data):")
print(pd.crosstab(df_mall_clusters['Cluster'], df_mall_clusters['Gender'], normalize='index'))Caracterización de los Segmentos (Mall Customer Data):
- Características: Ingresos anuales medios pero con un Spending Score bajo. Son clientes que probablemente visitan el centro comercial pero no gastan mucho.
- Estrategia: Ofrecer descuentos atractivos, programas de lealtad con recompensas inmediatas, y promociones de “prueba y compra” para incentivar el gasto.
- Características: Altos ingresos anuales y un Spending Score muy alto. Estos son los clientes VIP.
- Estrategia: Programas de fidelización premium, acceso exclusivo a eventos o ventas anticipadas, y recomendaciones personalizadas de productos de lujo o alta gama.
- Características: Mayoritariamente jóvenes, con ingresos anuales bajos pero un Spending Score muy alto.
- Estrategia: Enfocarse en moda juvenil, tecnología, entretenimiento y ofertas basadas en experiencias. Marketing a través de redes sociales e influencers.
- Características: Ingresos anuales bajos y un Spending Score bajo. Este es el segmento menos rentable.
- Estrategia: Identificar las razones de su bajo gasto (ej. falta de interés, solo compras de necesidad). Ofrecer productos básicos a precios competitivos o encuestas para entender sus necesidades y convertirlos.
- Características: Altos ingresos anuales pero un Spending Score bajo. Tienen el poder adquisitivo pero no lo ejercen en el centro comercial.
- Estrategia: Investigar por qué no gastan. Ofrecer experiencias de compra exclusivas, servicios personalizados (ej. personal shopper), y productos que se alineen con sus intereses de alto poder adquisitivo. Podrían necesitar un incentivo para empezar a gastar.
Conclusiones y Recomendaciones Futuras
La segmentación de clientes es una herramienta poderosa que transforma datos brutos en insights accionables. Como hemos visto, al agrupar clientes con características y comportamientos similares, las empresas pueden diseñar estrategias más efectivas y personalizadas, optimizando sus esfuerzos de marketing y mejorando la experiencia del cliente.
Los análisis realizados con el “Wholesale Customer Dataset” y el “Mall Customer Segmentation Data” demuestran cómo diferentes características pueden ser utilizadas para identificar segmentos de clientes únicos, cada uno con sus propias necesidades y preferencias. Desde minoristas que demandan grandes volúmenes de abarrotes hasta clientes de centros comerciales que buscan experiencias de compra de lujo, comprender estos matices es clave para el éxito empresarial.
Recomendaciones Futuras:
- Validación Externa: Si fuera posible, sería ideal validar los segmentos con datos externos o encuestas a clientes para confirmar que los grupos identificados se corresponden con la realidad del negocio.
- Segmentación Dinámica: Los comportamientos de los clientes cambian. Implementar un sistema de re-segmentación periódica (ej. trimestral o semestral) aseguraría que los segmentos sigan siendo relevantes y precisos.
- Análisis de Atributos Adicionales: Incorporar más datos (ej. datos demográficos más detallados, historial de interacciones con la marca, comentarios de clientes) podría enriquecer aún más la segmentación y ofrecer una visión más completa de los segmentos.
- Modelos Más Avanzados: Explorar algoritmos de clustering más complejos o técnicas de aprendizaje profundo para la segmentación si los datos lo justifican (ej. Autoencoders para reducción de dimensionalidad no lineal antes del clustering).
- Implementación y Monitoreo: Integrar los segmentos directamente en las plataformas de marketing y ventas, y monitorear continuamente el rendimiento de las estrategias implementadas para cada segmento.
La Ciencia de Datos es un campo en constante evolución, y la segmentación de clientes es solo una de las muchas aplicaciones que nos permiten tomar decisiones más inteligentes y basadas en datos. Al dominar estas técnicas, no solo mejoramos el rendimiento empresarial, sino que también creamos experiencias más significativas para los clientes.
Sobre el Autor
Este artículo fue redactado por un asistente de IA, que tiene como misión ayudar a democratizar el conocimiento en Ciencia de Datos y Machine Learning. Con el objetivo de compartir información valiosa y práctica, espero que este contenido te haya sido de gran utilidad en tu camino por el aprendizaje. Mi meta es hacer que conceptos complejos sean accesibles y aplicables, siempre con la convicción de que el conocimiento es una herramienta poderosa para el crecimiento.
¡Potencia tu Carrera en Ciencia de Datos!
Y recuerda que siempre, siempre, vas a aprender un bit a la vez!
🤖 Automatiza tu trading en 5 días con Python
Únete a mi Mini-Curso gratuito por email. Aprende a extraer datos reales, crear indicadores cuantitativos y hacer backtesting profesional.